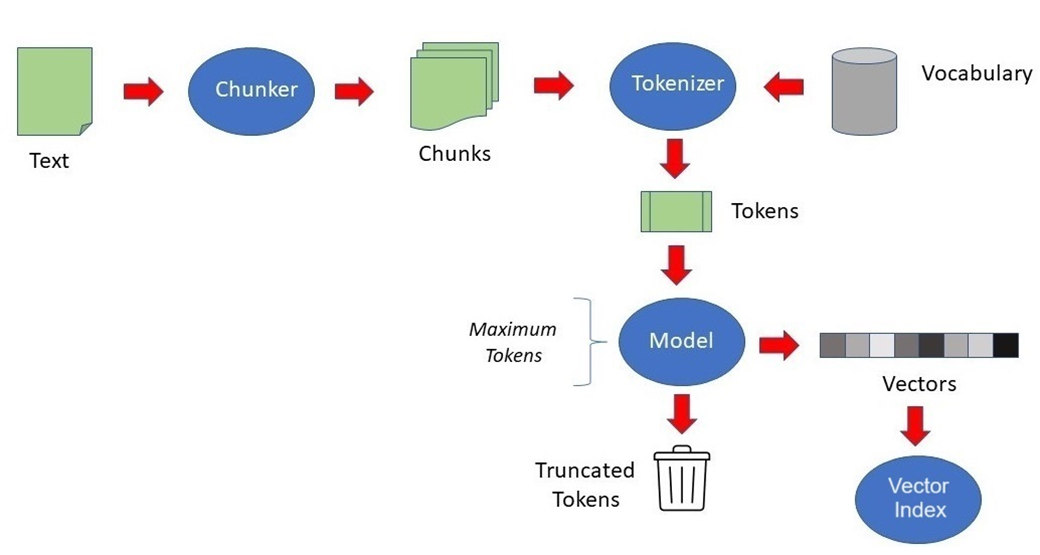
벡터인덱스 개념
벡터 임베딩에 대한 벡터 인덱스를 생성하고 이 인덱스를 사용하여 방대한 벡터 공간에서 유사성 검색을 실행할 수 있습니다.
벡터 인덱스는 고차원 벡터를 사용하여 유사성 검색을 가속화하도록 설계된 특수 인덱싱 데이터 구조의 한 종류입니다. 클러스터링, 분할 및 이웃 그래프와 같은 기술을 사용하여 유사한 항목을 나타내는 벡터를 그룹화하여 검색 공간을 크게 줄여 검색 프로세스를 매우 효율적으로 만듭니다.
현재 오라클에서 지원하는 벡터 인덱스의 종류는 2가지 입니다.
1. In-Memory Neighbor Graph = Hierarchical Navigable Small World (HNSW)
2. Neighbor Partition vector index = Inverted File Flat (IVF) index
IN-Memory Neighbor Graph Index는 계층적 탐색 가능한 소규모 세계(HNSW)유형을 지원하는 인덱스로 벡터 근사 유사성 검색을 위한 매우 효율적인 인덱스입니다.
HNSW 그래프는 계층적(Hierarchical) 구조와 함께 탐색 가능한 소규모 세계(NSW) 네트워크의 원칙을 사용하여 구조화됩니다.
Neighbor Partition vector index는 Inverted File Flat(IVF) Index 를 유일하게 지원하는 벡터 유형의 인덱스입니다. IVF는 높은 검색 품질과 적당한 속도의 균형을 이루는 분할 기반 인덱스입니다.
이웃 파티션 또는 클러스터를 사용하여 검색 영역을 좁혀 검색 효율성을 높이기 위해 고안된 기술입니다.
HNSW (Hierachical Navigable Small World) 인덱스 이해
HNSW는 Hierarchical Navigable Small World의 약자로 여러 알고리즘들의 결합으로 만들어져 있습니다.
결합된 알고리즘을 분해해서 살펴보면 Small World 특성을 바탕으로 효율적인 경로를 탐색 가능하게 하는 NSW(Navigable Small World)라는 알고리즘에 Skip List의 개념을 적용하여 NSW 그래프를 계층화한 HNSW (Hierachical Navigable Small World) 알고리즘이 만들어지게 되었습니다.
Navigable Small World(NSW)를 사용하면 그래프의 각 벡터가 세 가지 특성을 기반으로 여러 다른 벡터에 연결되는 근접 그래프를 구축하는 것이 목표입니다.
1. 벡터 사이의 거리
2. 삽입 중 검색 과정에서 각 단계에서 고려되는 가장 가까운 벡터 후보들의 최대 수 (EFCONSTRUCTION)
3. 벡터당 허용되는 최대 연결 수(NEIGHBORS)
위의 두 임계값의 조합이 너무 높으면 밀집 연결 그래프가 되어 검색 프로세스가 느려질 수 있습니다.
반면, 해당 임계값의 조합이 너무 낮으면 그래프가 너무 희소하거나 연결이 끊어져서 검색 중에 특정 벡터 간의 경로를 찾기 어려울 수 있습니다.
HNSW 벡터 인덱스는 In-Memory 인덱스이므로 인덱스 세그먼트가 생성되지 않으며, 암시적으로 추가 오브젝트를 생성합니다. *_INDEXES 뷰를 조회하면 2개의 B-tree 인덱스와 3개의 테이블이 생성된 것을 확인할 수 있습니다.
Small World 6단계의 법칙
| 출처 § THE ORACLE OF BACON(https://oracleofbacon.org/) § NHN Forward 22 - 벡터 검색 엔진에 ANN HNSW 알고리즘 도입기(https://inspirit941.tistory.com/504) § 자료구조와 알고리즘 - 벡터 검색 엔진 최적화 방법: HNSW(Hierarchical Navigable Small World Graphs) (https://kokoko12334.tistory.com/m/entry/hsfl) § Hierarchical Navigable Small World Graph로 nearest neighbor를 빠르게 찾아 보자. (https://ita9naiwa.github.io/ml/2019/10/04/hnsw.html) § 검색증강생성(RAG) - 그래프 기반 벡터 인덱스 HNSW(Hierarchical Navigable Small World) (https://jerry-ai.com/30) |
스몰월드는 케빈 베이컨 게임으로 설명으로 쉽게 설명이 됩니다.
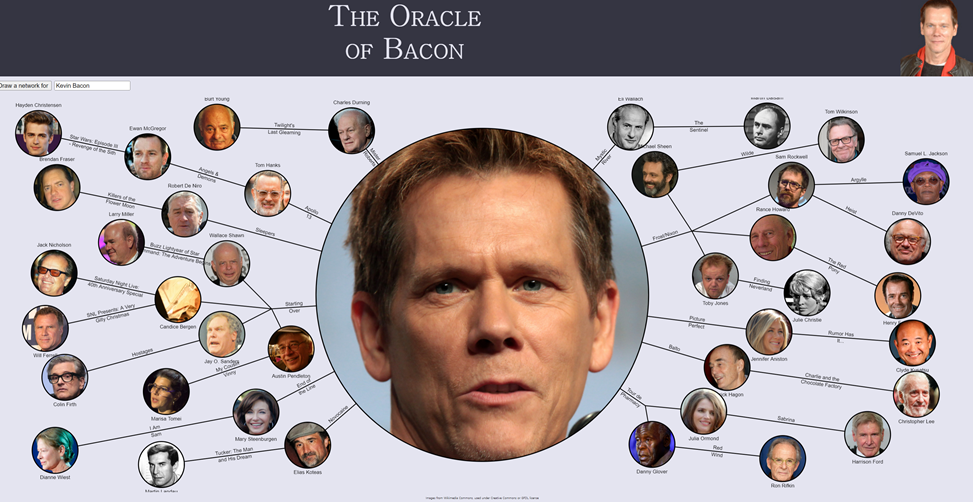
우리나라의 유명 배우 중 한명인 송강호 배우가 있습니다. 송강호 배우는 케빈 베이컨과 몇 단계를 거치면 도달할 수 있을까요? 놀랍게도 3단계만에 송강호 배우와 케빈 베이컨배우가 연결이 됩니다.
케빈 베이컨은 어퓨굿맨 이라는 영화에서 톰 크루즈와 함께 출연을 했습니다. 톰 크루즈는 바닐라 스카이라는 영화에서 틸다 스윈튼배우와 같이 출연을 했습니다. 틸다 스윈튼배우는 설국열차에서 송강호 배우와 같이 출연을 했습니다. 정리를 해보면 아래와 같은 관계가 형성이 됩니다.
케빈 베이컨-어퓨굿맨-톰 크루즈-바닐라스카이-틸다 스윈튼-설국열차-송강호
그렇다면 케빈 베이컨과 우리나라 배우들과의 관계도 많아야 4~5단계안에 형성이 될 수 있습니다.
이 관계를 일반화해서 전세계에 있는 사람들을 대상으로 생각해 보겠습니다. 전세계에 있는 사람들도 평균적으로 6단계를 거치면 만날 수 있다라는 네트워크 이론 “6단계 법칙”이 만들어지게 되었습니다.
Small World
위의 베이컨 게임을 통해서 보았듯 우리는 수학적으로 6단계안에 관계가 형성되고 있고, 이러한 법칙을 바탕으로 Small World(작은 세계)라는 개념이 탄생하게 되었습니다. 스몰월드라는 네트워크 이론을 조금 더 살펴보겠습니다.
아래의 그래프처럼 모든 네트웍은 그 연결 방식에 따라 크게 세 가지로 나눠질 수 있습니다.
일정한 규칙에 따라 인접한 곳과 일정한 숫자로만 링크되는 'regular network'이 있고,
무작위로 서로 연결되어 있는 'random network'이 있습니다.
그리고 이 둘의 중간쯤에 있는 Small-world가 있습니다.
스몰월드는 구성원의 일부만이 전혀 엉뚱한 곳으로 연결되어 있는 네트워크입니다.

Small World Network를 도식화 한 그래프에서 스몰월드의 상태를 알아보겠습니다.
가장 왼쪽에 있는 그래프는 모든 Edge(간선,선)이 고르게(Regular) 연결되어 있는 상태입니다.
가장 오른쪽 그래프는 모든 Edge가 Random으로 연결된 상태입니다.
왼쪽에 있는 Regular 그래프에서 몇개의 노드를 Random 연결시켜 봤더니 평균적으로 노드에 도달하는 거리의 수가 확연히 줄어드는것을 볼 수 있습니다.
중간에 있는 Small-world 그래프는 위에 설명처럼 Regular그래프에서 3개의 노드를 랜덤으로 추가하여 연결했더니 전체적인 노드의 길이가 줄어들었습니다.
즉, 전체 네트워크가 거대하더라도 일부의 특정 노드에 의해서 전체가 서로 가깝게 연결될 수 있다는 것을 의미합니다.
Small world의 이론적인 특징을 정리해보면 다음과 같습니다.
1. 짧은 평균 경로 길이 : 베이컨 게임에서 보았듯 Small world 네트워크에서 네트워크 내의 임의의 두 노드 사이의 평균거리는 매우 짧습니다.
2. 높은 클러스터링(높은 군집계수) : 이 네트워크는 노드들이 지역적으로 밀집된 클러스터를 형성하는 경향이 있습니다. 즉, 한 노드의 이웃 노드들이 서로 연결되어 있을 가능성이 큽니다. “내 친구의 친구도 내 친구일 가능성이 높다”라는 상황으로 나타날 수 있습니다.
3. 긴 거리 연결 : 비교적 멀리 떨어져있는 노드들이 특별한 연결을 통해 서로 직접 연결되는 것을 의미합니다. 긴 거리 연결(long-range link)" 또는 "지름길(shortcut)로 불리는 이 연결을 통해 전체의 연결성을 크게 개선됩니다.
NSW(Navigable Small World)
NSW는 Small-World Network 특성을 유지하면서 현재 위치에서 가장 가까운 이웃 노드로 이동하여 최단 경로를 찾을 수 있는 네트워크 구조를 말합니다.
아래의 그림은 각 벡터값을 표현한 그림입니다.

검정색 선은 Regular로 표현된 경로이고, 빨간색 선은 Small World의 특징 중 하나인 Long-range link를 표현한 것 입니다. 시작점인 entry point에서 목표점인 query 벡터를 찾아가보도록 하겠습니다.
검은색 노드들만 따라갔을 때 4개의 노드를 거쳐서야 가장 가까운 이웃 노드로 이동이 되었는 반면,small world를 적용한 빨간색 노드와 섞어서 찾아 갔을때 3개의 노드만 거쳐서 가장 가까운 이웃 노드로 이동이 된 것을 확인할 수 있습니다.
하지만 NSW 알고리즘에도 단점이 있습니다.
바로 local minimum에 빠질 수 있다는 문제입니다.
NSW(Navigable Small World)의 문제점
NSW의 문제점인 local minimum에 대해 알아보겠습니다.
Local Minimum : 미니멈은 탐색 과정이 더 이상 진전되지 않는 지점을 의미.
네트워크 탐색 과정에서 발생할 수 있는 문제 중 하나로, 목적지에 도달하기 위해 최단 경로를 찾으려는 탐색이 더 이상 진행되지 않고 멈추는 지점을 의미합니다. 이 지점에서는 더 이상 목적지로 가까워지지 않거나, 오히려 목적지에서 멀어지게 되는 상황이 발생할 수 있습니다.
실생활을 통해서 예를 들면, 회사의 위치가 서울시 서초구에 위치해 있는데 주소에 대한 링크수가 작다고 하면 회사의 주소는 서울시다 라는 Local minimum에 빠질 위험성이 있습니다. 반대로 링크 수를 많이 늘리면 서초구 서초**빌딩 이라는 주소가 나오겠지만 찾아가는 단계는 서울시를 찾는 단계보다 복잡해집니다.
서버의 입장에서 보면 링크수가 늘어나면 정확도는 높아지지만 탐색 시간과 자원은 늘어나게 되는것입니다. 그렇기에 정확도와 자원의 적정선을 찾는 튜닝이 필요합니다.
아래에 그래프를 통해 Local Minimum이 발생하는 것을 확인해보겠습니다.

쿼리 벡터 V와 네트워크 내 가장 가까운 노드를 탐색할 때, 해당 Entry 진입점에서 시작하여 Greedy 탐색을 통해 가장 가까운 노드를 찾을 수 있습니다.

하지만 위의 진입점에서 출발하여 Greedy 방식을 적용하면 가장 가까운 노드가 아닌 노드를 선택합니다.
이를 Local minimum 이라고 합니다. 이를 해결하는 방법 중에 하나는 연결하는 링크 수(m)를 늘리는 것입니다. 하지만 이는 정확도가 높아지지만 그만큼 탐색 시간이 늘어나게 됩니다.
이 문제를 해결하기 위해서 계층 구조(Hierachical)를 추가합니다.
계층 구조를 알아보기 전 Greedy알고리즘을 보고 넘어가겠습니다.
Greedy 알고리즘
Greedy 알고리즘 : 최적의 값을 구해야 하는 상황에서 사용되는 근시안적인 방법론.
아래의 그림으로 Greedy 알고리즘을 사용해서 “노드에서 합이 가장 높은 방법”을 찾는 문제를 해결해보겠습니다.
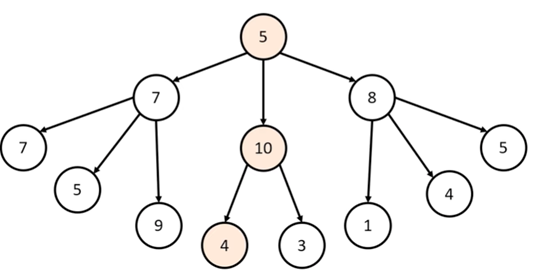
1. 처음에는 루트노드에서 시작하므로 5인 정점을 선택이 됩니다.
2. 두번째는 브런치노드에서 3개의 정점 7,10,8에 대해 비교 후 현재 노드에서 가장 큰 10을 선택합니다.
3. 마지막으로 리프노드에서 2개의 정점 4,3에 대해 비교 후 4를 선택합니다.
Greedy(탐욕) 알고리즘은 현재 상황에서 가장 적합한 답안을 찾으므로 정답과는 다를 수 있습니다. 아래의 그림에서는 5->7->9의 합인 21이 정답이지만 greedy 알고리즘을 사용했을 시에는 노드당 가장 큰 값을 선택하므로 5->10->4로 합이 19인 답안이 나오게 됩니다.
Skip list
앞에서 NSW의 문제점인 Local minimum을 해결하기 위해 계층을 추가하여 HNSW (Hierarchical Navigable Small World)를 만들었습니다.
HNSW(Hierachical Navigable Small World)는 근사 최근접 이웃 탐색(Approximate Nearest Neighbor Search)을 위해 사용되는 알고리즘으로 NSW에 문제점인 로컬미니멈을 해결하기 위해 skip list의 개념을 적용하여, NSW 그래프를 계층화한 알고리즘입니다.
계층을 효율적으로 나누기 위해서 Skip list 개념을 사용하는데 잠깐 알아보고 HNSW로 넘어가겠습니다.
기존의 단일 연결 리스트에서 숫자 6에 접근하려면, 진입점부터 시작해 각 노드를 순차적으로 접근해야 합니다.
스킵 리스트는 이러한 단점을 해결하기 위해 다중 레벨을 도입하여 더 빠르게 탐색할 수 있게 합니다. 스킵 리스트는 여러 레벨의 연결 리스트로 구성되어 있으며, 각 레벨은 하위 레벨의 노드를 건너뛸 수 있는 포인터를 포함합니다.
Skip list 에는 두가지에 유형이 있습니다.
하나는 완전 스킵리스트이고, 나머지 하나는 랜덤 스킵리스트(=확률 스킵리스트) 입니다.
HNSW에서 사용하는 스킵리스트의 유형은 확률 스킵리스트이므로, 완전 스킵리스트는 간략하게만 살펴보겠습니다.
- 완전 스킵리스트 : 스킵하는 레벨을 규칙적으로 정해서 구성하는 방법입니다.


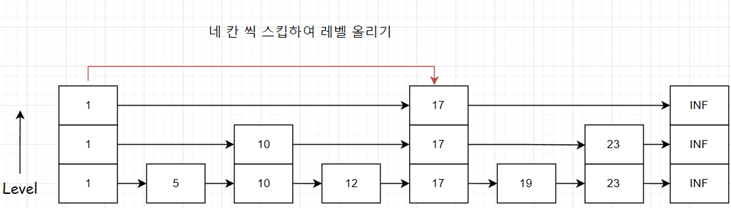
완전 스킵리스트의 방식은 고정된 패턴으로 인해 유연성이 부족하고 특정 상황에서는 비효율적일 수 있습니다.
검색은 빠르지만, 삽입과 삭제 연산에서 비효율적인 구조를 갖게 됩니다. 삽입과 삭제 하는 연산에서 스킵 리스트를 재구성해야하기 때문입니다.
이를 해결하기 위한 방법이 랜덤 스킵리스트입니다.
- 확률(랜덤) 스킵리스트 : 각 레벨의 노드가 확률적으로 결정되는 방식.
랜덤 스킵리스트는 확률적 접근 방법을 통해 삽입 및 삭제 과정을 더욱 효율적으로 만들어줍니다.
아래에 그래프를 통해 확인해보겠습니다.

- 레벨 1에서는 모든 노드가 존재하므로 확률이 1입니다.
- 레벨 2에서 노드를 가질 확률은 1/2입니다.
- 레벨 3에서 노드를 가질 확률은 1/4입니다.
- 레벨 k에서 노드를 가질 확률은 1/(2^(k-1))입니다.
예를 들어, 2 레벨에 노드를 배치할 확률이 1/2, 3 레벨에서는 1/4인 식으로 재귀적으로 적용됩니다. 이를 통해 삽입 및 삭제 과정에서도 평균적인 시간 복잡도를 유지할 수 있습니다.
이와 같은 확률 할당 방식은 노드가 상위 레벨로 갈수록 점점 더 적어지도록 만들며, 이를 통해 노드들의 탐색시간을 줄일 수 있습니다.
| 참고 - 체크: 오라클에서는 HNSW인덱스가 있는 테이블은 DML문이 안됩니다. ORA-51928: 인메모리 인접 그래프 벡터 인덱스가 있는 테이블에서는 DML(데이터 조작어)이 지원되지 않습니다. 오라클 DB에서는 DML문이 되지 않으므로 확률 스킵리스트의 삽입 및 삭제의 이점이 작습니다. 하지만, INDEX를 생성시에 삽입의 이점을 받을 수 있고, EFCONSTRUCTION 파라미터를 통해 조정할 수 있습니다. 인덱스를 스토리지가 아닌 메모리 공간에 생성하여 사용하기 때문에 DML문이 제한 되지않을까라는 생각이 듭니다. 그럼에도 불구하고 확률 스킵리스트를 채택한 이유는 HNSW 알고리즘에서 확률형 스킵리스트가 탐색 효율성을 높이는데 효과가 있고, 메모리의 효율성 또한 높일 수 있기 때문이라고 생각이 듭니다. - EFCONSTRUCTION:삽입 중 검색의 각 단계에서 고려되는 가장 가까운 벡터 후보의 최대 개수 |
HNSW(Hierarchical Navigable Small World)
여러 복잡한 알고리즘들을 알아본 끝에 앞에 알고리즘들의 결합인 HNSW에 대해 알아보겠습니다. 위에서 설명한 바와 같이 HNSW(Hierachical Navigable Small World)는 근사 최근접 이웃 탐색(Approximate Nearest Neighbor Search)을 위해 사용되는 알고리즘으로 NSW에 문제점인 로컬미니멈을 해결하기 위해 skip list의 개념을 적용하여, NSW 그래프를 계층화한 알고리즘입니다.
위에서 학습한 Skip list를 계층화 하여 NSW에 적용을 하면 다음과 같습니다.

시작점은 Entry Pioint인데 가장 높은 계층인 Entry Layer에서 시작을 합니다.
해당 계층에서 가장 가까운 정점을 찾고 다음 계층으로 내려갑니다.
다음계층으로 내려간 뒤 해당 계층에서 가장 가까운 정점을 찾고 다음 계층으로 내려간 후 가장 낮은 계층에서 사용자의 질의 벡터(vq)와 가장 근접한(Nearest Neighbor) 벡터를 찾습니다.
이때 계층과 노드가 작으면 Local minimum에 빠질 수 있고, 너무 많으면 시간과 자원의 소모가 커질 위험이 있습니다.
높은 레이어에서는 노드의 수가 작고, 인접한 노드 사이의 거리가 깁니다.
낮은 레이어로 갈수록 노드의 수가 많고, 인접한 노드 사이의 길이가 짧아집니다.
실생활에서 예를 들어보겠습니다.
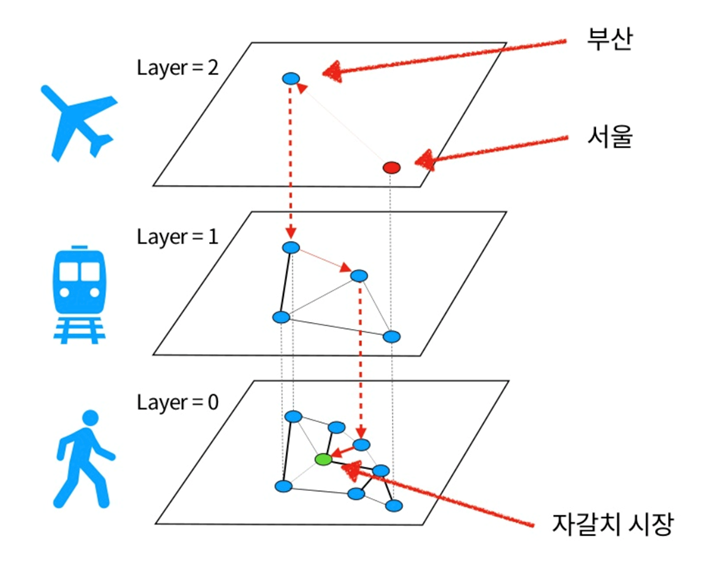
노드 사이의 거리를 효율적으로 계산하기 위해 확률 스킵리스트를 적용해서 노드들을 계층화 합니다.
강릉에서 자갈치 시장을 찾아가는 방법을 생각해봅니다. 시간이라는 자원을 아끼기 위해 가장 상위 계층에서 시작합니다. 서울을 경유해서 가는 거리로만 보면 자갈치 시장으로 바로 가는 직선거리가 가장 짧습니다. 하지만 바로 가기에는 시간이라는 자원이 많이 소모가 됩니다.
그래서 비행기를 타고 한번에 부산까지 이동을합니다. 여기서 비행기는 탈수있는 곳이 적고 한번에 멀리 이동할 수 있는 특징이 있습니다.
HNSW 그래프에서도 동일합니다. 최 상위계층의 특징은 노드간의 거리가 멀고 정점의 수가 적습니다.
부산 까지 이동을 한 후 자갈치 시장으로 가기위해서 지하철을 타고 이동을 합니다.
자갈치 시장에 가장 가까운 지하철역 내립니다.
이 과정을 HNSW에서 보면 가장 근접한(Nearest Neighbor) 벡터를 찾는 방법과 동일합니다.
마무리
ORACLE Vector Index를 공부하면서 여러 알고리즘들을 접하였는데, 이해가 쉽지않았습니다. 이곳저곳을 찾아가며 정보를 얻은것들을 바탕으로 작성했는데, 오라클에서 추구하는 HNSW와 조금 차이가 있을 수 있습니다.
ORACLE Document에서는 간략하게만 설명이 나와있어서 추가적인 정보를 붙여서 정리했는데 도움이 되었으면 좋겠습니다.
'ORACLE 23ai' 카테고리의 다른 글
| ORACLE 23ai RAG(증강검색) 실습 (4) | 2024.09.19 |
|---|---|
| Oracle Embedding Model Load (1) | 2024.09.05 |
| Embedding (1) | 2024.08.28 |
| RAG(검색 증강 생성)이란 (0) | 2024.08.26 |