들어가며
오라클의 23ai Document 를 보고 정리한 내용입니다.
ORACLE Document URL :https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/index.html
23ai 공개 이후 AI에 대해 관심이 생겨 여러 자료들을 찾아보며 RAG(증강검색생성)까지 진행을 해봤습니다.
RAG를 할수록 원본 데이터의 품질이 중요하다고 느껴졌습니다.
아직 청킹을 잘 하는 방법에 대해서는 이것저것 테스트를 해보고 있습니다.
우선 LLM과 RAG를 하기 전 데이터를 청킹하고 모델을 통해 임베딩을 하는 과정을 소개하려고 합니다.
Embedding이란?
Oracle AI Vector Search는 Oracle Database 내부 또는 외부의 비정형 데이터에서 벡터 임베딩을 자동으로 생성하는 Vector Utilities(SQL 및 PL/SQL 도구)를 제공합니다.
벡터 임베딩 모델은 단어, 문장 또는 단락과 같은 데이터의 각 요소에 숫자 값을 할당하여 임베딩을 만듭니다.
데이터베이스 내에서 임베딩을 생성하려면 ONNX 형식의 벡터 임베딩 모델을 가져와 사용할 수 있습니다. 데이터베이스 외부에서 임베딩을 생성하려면 타사 REST API를 호출하여 타사 벡터 임베딩 모델에 액세스할 수 있습니다.
데이터 변환 단계 이해
입력 데이터는 벡터로 변환되기 전에 여러 단계를 거칠 수 있습니다.
예를 들어, 텍스트 데이터(예: PDF 문서)를 일반 텍스트로 변환한 다음, 결과 텍스트를 더 작은 텍스트 조각(청크)으로 나누어 마지막으로 각 청크에 벡터 임베딩을 생성할 수 있습니다.
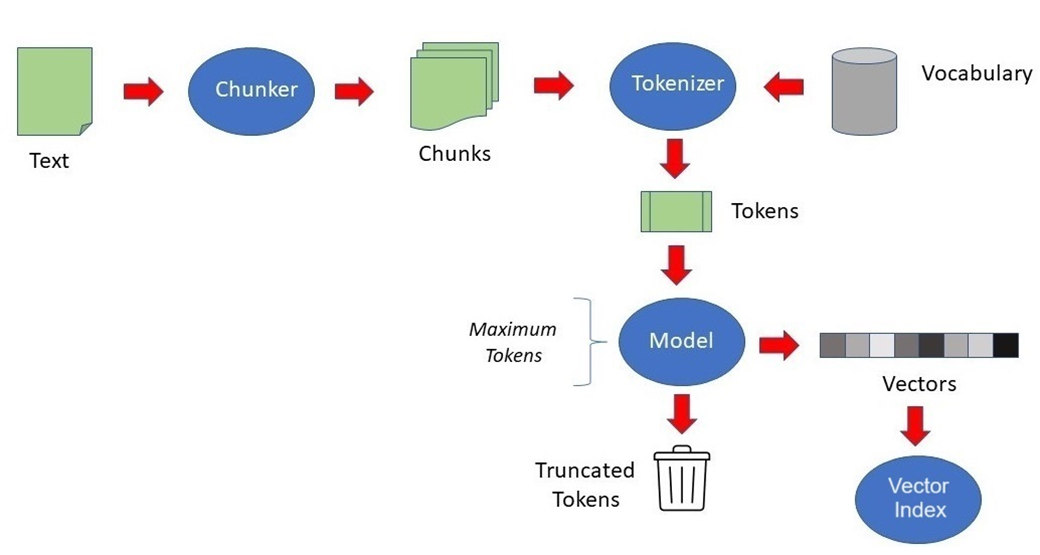
위 그림은 입력 데이터가 벡터로 변환되기 전에 통과하는 단계의 파이프라인을 보여줍니다.
1) PDF등의 텍스트를 Chunker가 청크(Chunks)로 생성하고,
2) 생성된 청크를 Tokenizer가 토큰(Tokens)으로 생성하고,
( 별도로 Vocabulary는 토큰이 처리되기 전에 Tokenizer로 전달됩니다.)
3) 토큰이 Embedding Model을 통해 벡터(Vector)로 생성됩니다.
4) 마지막으로 Vector가 Vector Index에 저장되는 것을 보여줍니다.
위의 데이터 변환 파이프라인을 데이터적인 관점에서 조금 더 알아보겠습니다.

각 파이프라인 또는 변환 체인(transformation chain)은 단일 함수 또는 함수 조합을 포함할 수 있으며, 이는 소스 문서가 다른 표현(텍스트, 청크, 요약 또는 벡터)으로 변환될 때 적용됩니다.
각 체인 가능 유틸리티 함수는 데이터를 다른 표현으로 변환하는 특정 작업을 수행합니다. 예를 들어 데이터를 텍스트로 변환하거나, 텍스트를 청크로 변환하거나, 추출된 청크를 임베딩으로 변환하는 작업을 수행합니다.
체인 가능한 유틸리티 함수는 유연하고 모듈화되도록 설계되었습니다.
위 그림에서 볼 수 있듯이 파일-텍스트-청크-임베딩 체인은 다음 순서로 일련의 작업을 수행합니다.
① PDF 파일을 일반 텍스트로 변환합니다(UTL_TO_TEXT)
② 결과 텍스트를 적절한 크기의 청크로 분할합니다(UTL_TO_CHUNKS)
③ 각 청크에 벡터 임베딩을 생성합니다(UTL_TO_EMBEDDINGS)
파일-텍스트-청크-임베딩 체인을 쿼리를 통해 확인해보겠습니다.
파일을 일반 텍스트로 변환(UTL_TO_TEXT)
select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ;
텍스트로 변환된 데이터를 청킹(UTL_TO_CHUNKS)
select t.*
FROM (select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ) dc
CROSS JOIN TABLE (
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(dc.DOC_CONTENT_BLOB)
,json('{"by":"characters","max":"3000","split":"none","normalize":"all","LANGUAGE":"KOREAN"}'))) t;
parameter :
- BY:CHARACTERS(문자 수를 세어 나눔)
- MAX:3000(각 청크의 최대 크기에 대한 제한을 지정합니다. 최대 크기 제한에 도달하면 데이터를 분할합니다.)
- SPLIT:NONE(입력 텍스트가 최대 크기 제한에 도달했을 때 분할할 위치를 지정합니다. NONE은 한계 에서 분할하는 의미)
- NORMALIZE:all(문서를 텍스트로 변환할 때 발생할 수 있는 문제(여러 개의 연속된 공백 및 smart quotes(굽은 따옴표(‘’,“”)) 등)를 자동으로 전처리하거나 후처리합니다. all=유니코드 구두점을 standard single-byte로 정규화합니다.)
- LANGUAGE:KOREAN(언어는 한국어)
각 청크에 벡터 임베딩을 생성(UTL_TO_EMBEDDINGS)
select t.*
FROM (select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ) dc
CROSS JOIN TABLE (
dbms_vector_chain.utl_to_embeddings(
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(dc.DOC_CONTENT_BLOB)
,json('{"by":"characters","max":"3000","split":"none","normalize":"all","LANGUAGE":"KOREAN"}')),
json('{"provider":"database", "model":"ONN.DISTILUSE_BASE_MULTILINGUAL_CASED_V2"}'))) t
CROSS JOIN JSON_TABLE(t.column_value, '$[*]' COLUMNS ( embed_vector CLOB PATH '$.embed_vector')) AS et;
[표: 제공되는 체인 가능한 유틸리티 함수]
| 기능 | 설명 | 입력 및 반환 값 |
| UTL_TO_TEXT() | 데이터(예: Word, HTML 또는 PDF 문서)를 일반 텍스트로 변환합니다. | CLOB 또는 BLOB로 입력을 허용합니다. 문서의 일반 텍스트 버전을 CLOB로 반환합니다 |
| UTL_TO_CHUNKS() | 데이터를 청크로 변환합니다. | 입력을 일반 텍스트(CLOB 또는VARCHAR2)로 허용합니다. 데이터를 분할하여 청크 배열(CLOB)을 반환합니다. |
| UTL_TO_EMBEDDING() | 데이터를 단일 임베딩으로 변환합니다. | 입력을 일반 텍스트(CLOB)로 허용합니다. 단일 임베딩(VECTOR)을 반환합니다. |
| UTL_TO_EMBEDDINGS() | 청크 배열을 임베딩 배열로 변환합니다. | 입력을 청크 배열(VECTOR_ARRAY_T)로 허용합니다. 임베딩 배열(VECTOR_ARRAY_T)을 반환합니다. |
| UTL_TO_SUMMARY() | 크거나 복잡한 문서와 같은 데이터에 대한 간결한 요약을 생성합니다. | 입력을 일반 텍스트(CLOB)로 허용합니다. 일반 텍스트의 요약을 CLOB로 반환합니다. |
| UTL_TO_GENERATE_TEXT() | 프롬프트에 대한 텍스트를 생성합니다. | 입력을 텍스트 데이터(CLOB)로 허용합니다. 이 정보를 처리하여 생성된 텍스트가 포함된 CLOB를 반환합니다. |
청크(Chunk) 작업
임베딩에서 알고리즘도 중요하지만 가장 중요한 것중 하나는 긴 문서를 어떻게 파편으로 잘라낼것인가? (이를 영어로 Chunking이라고 한다.) 입니다.
오라클 데이터베이스는 텍스트를 분할을 위한 유틸리티 패키지인 DBMS_VECTOR_CHAIN 패키지를 제공합니다. 문서용 텍스트 데이터, 텍스트 데이터의 청크 분할, 콘텐츠 요약 및 임베딩을 모두 데이터베이스내에서 처리할수 있습니다.
청킹 기능은 VECTOR_CHAIN 패키지 내 VECTOR_CHUNKS 함수를 통해 사용이 가능합니다.
데이터를 일반 텍스트로 변환한 다음 결과 텍스트를 Chunker로 전달합니다. 그런 다음 chunker는 chunking 이라는 프로세스를 사용하여 텍스트를 더 작은 청크로 나눕니다.
청킹에는 세부적인 파라미터들이 많아 아래에 표에 정리하였습니다.
VECTOR_CHUNKS parameters
| Parameter | Description and Acceptable Values |
| BY | 데이터 분할 모드를 지정합니다. 즉, 문자, 단어 또는 어휘 토큰의 수를 세어 분할합니다. 유효한 값 : · BY CHARACTERS(또는 BY CHARS): 문자 수를 세어 나눕니다. · BY WORDS: 단어의 개수를 세어 나눕니다. 단어는 알파벳 문자 시퀀스, 숫자 시퀀스, 개별 구두점 또는 기호로 정의됩니다. 공백 단어 경계가 없는 분할 언어(예: 중국어, 일본어 또는 태국어)의 경우 각 모국어 문자는 단어(즉, 유니그램)로 간주됩니다. · BY VOCABULARY: 어휘 토큰의 개수를 세어 나눕니다. 어휘 토큰은 임베딩 모델이 사용하는 토크나이저의 어휘로 인식되는 단어 또는 단어 조각입니다. VECTOR_CHUNKS helper API 사용하여 어휘 파일을 로드할 수 있습니다 DBMS_VECTOR_CHAIN.CREATE_VOCABULARY. 참고 : 정확한 결과를 얻으려면 선택한 모델이 청크에 사용된 어휘 파일과 일치하는지 확인하십시오. 어휘 파일을 사용하지 않는 경우 입력 길이가 모델의 토큰 제한 내에서 정의되었는지 확인하십시오. 기본값 :BY WORDS |
| MAX | 각 청크의 최대 크기에 대한 제한을 지정합니다. 이 설정은 더 큰 텍스트에서 최대 제한이 발생하는 고정된 지점에서 입력 텍스트를 분할합니다. 단위는 모드 MAX에 해당합니다 BY. 즉, 특정 수의 문자, 단어, 숫자, 구두점 또는 어휘 토큰의 최대 크기 제한에 도달하면 데이터를 분할합니다. 유효한 값 : · BY CHARACTERS: 50 to 4000 characters · BY WORDS: 10 to 1000 words · BY VOCABULARY: 10 to 1000 tokens 기본값 :MAX 100 |
| SPLIT [BY] | 입력 텍스트가 최대 크기 제한에 도달했을 때 분할할 위치를 지정합니다. 이는 청크에 대한 적절한 경계를 정의하여 관련 데이터를 함께 유지하는 데 도움이 됩니다. Valid values: 1. NONE: MAX문자, 단어 또는 어휘 토큰의 한계 에서 분할됩니다 . 2. NEWLINE, BLANKLINE, and SPACE: MAX 값 이전의 마지막 분할 문자에서 분할되는 단일 분할 문자 조건입니다. NEWLINE을 사용하여 텍스트 행의 끝에서 분할합니다. BLANKLINE을 사용하여 공백 행의 끝(예: 두 줄의 새 행)에서 분할합니다. SPACE를 사용하여 공백 행의 끝에서 분할합니다. · RECURSIVELY: 이것은 문자(또는 시퀀스)의 순서대로 나열된 목록을 사용하여 입력된 텍스트를 깨는 다중 분할 문자 조건입니다. RASCERIESS는 다음 순서로 블랭크 라인, 새 라인, 스페이스, 없음으로 미리 정의됩니다: 1. 입력 텍스트가 MAX 값보다 크면 첫 번째 분할 문자로 분할합니다. 2. 실패할 경우 두 번째 분할 문자로 분할합니다. 3. 등등. 4. 분할 문자가 없는 경우 텍스트에 표시되는 곳마다 MAX로 분할합니다. · SENTENCE: 문장 경계에서 입력된 텍스트를 끊는 문장 끝 분할 조건입니다. 이 조건은 입력 언어의 문장 문장부호에 대한 지식과 문맥 규칙을 사용하여 문장 경계를 자동으로 결정합니다. 이 언어별 조건은 대부분 EOS(End-of-Sentence) 문장부호와 일반적인 약어에 의존합니다. 문맥 규칙은 단어 정보를 기반으로 하므로 이 조건은 텍스트를 단어 또는 어휘로 분할할 때만 유효합니다(not by characters). Note: 이 조건은 BY WORD 및 MAX 설정을 따르므로 경우에 따라 정확한 문장 경계를 결정할 수 없습니다. 예를 들어, 문장이 MAX 값보다 크면 MAX에서 문장을 분할합니다. 마찬가지로 MAX 한계 내에 맞는 경우에만 텍스트에 여러 문장을 포함합니다. · CUSTOM: 사용자 정의 분할 문자 목록에 따라 분할합니다. 각각 최대 10개의 길이로 최대 16개의 분할 문자 문자열로 사용자 정의 시퀀스를 제공할 수 있습니다. 다음과 같이 유효한 텍스트 리터럴을 제공합니다: tab(\t), newline(\n), linefeed (\r)에 대해서만 시퀀스를 생략할 수 있습니다. Default value: RECURSIVELY |
| OVERLAP | 청크가 포함해야 할 이전 텍스트의 양(양의 정수 리터럴 또는 0)을 지정합니다. 이는 이전 청크 텍스트의 일부 양을 포함하여 관련 텍스트(예: 문장)를 논리적으로 분할하는 데 도움이 됩니다. 중복의 양은 청크의 최대 크기를 측정하는 방법(문자, 단어 또는 어휘 토큰)에 따라 달라집니다. 중복은 지정된 SPLITE 조건(예를 들어 NEWLINE에서)에서 시작됩니다. Valid value: 5% to 20% of MAX Default value: 0 |
| LANGUAGE | 입력 데이터의 언어를 지정합니다. 이 절은 특히 텍스트에 다른 언어로 다르게 해석될 수 있는 특정 문자(예: 구두점 또는 약어)가 포함되어 있는 경우 중요합니다. Valid value: Oracle Database Globalization Support Guide에 나열된 모든 NLS 지원 언어 이름 또는 언어 약어. 공백이 있는 모든 언어 이름에는 반드시 double quotation(")을 사용해야합니다. For example: LANGUAGE "simplified chinese" 한 단어 언어 이름의(one-word language names) 경우 quotation 표시가 필요하지 않습니다. For example: LANGUAGE american Note: DBMS_VECTOR_CHAIN.CREATE_LANG_DATA chunker helper API를 사용하여 지정된 언어에 대해 언어별 데이터(약어 tokens)를 데이터베이스에 로드할 수 있습니다. Default value: NLS_LANGUAGE from session |
| NORMALIZE | 문서를 텍스트로 변환할 때 발생할 수 있는 문제(여러 개의 연속된 공백 및 smart quotes(굽은 따옴표(‘’, “”)) 등)를 자동으로 전처리하거나 후처리합니다. 오라클은 이 모드를 사용하여 품질이 좋은 청크를 추출하는 것을 권장합니다. Valid values: · NONE: 정규화를 지정하지 않습니다. · ALL: 공통 다중 바이트(유니코드) 구두점을 standard single-byte로 정규화합니다. · PUNCTUATION: smart quotes, smart hyphens 및 기타 단일 바이트 구두점과 동일한 멀티 바이트를 포함합니다. For example: o 2018u 'map to 0027' o 2019u 'map to 0027' o 201Bu 'map to 0027' · WHITESPACE: 불필요한 문자를 제거하여 공백을 최소화합니다. For example, blanklines은 유지하되, 추가로 newlines,spaces,tabs 는 제거합니다: " \n \n " => "\n\n" · WIDECHAR: 넓고 다중 바이트인 숫자와 (az) 문자를 단일 바이트로 정규화합니다. 0-9 및 a-z A-Z로 된 다중 바이트이며 , ZH/JA 형식 텍스트로 표시할 수 있습니다. Note: 쉼표로 구분된 여백(WHITESPACE), 구두점(PUNCTUATION), and WIDECHAR 괄호 목록(WIDECHAR in parentheses)을 반드시 지정해야합니다. Default value: None |
| EXTENDED | MAX_STRING_SIZE 매개 변수를 EXTED로 설정할 필요 없이 VARCHAR2 문자열의 출력 제한을 32767bytes로 늘립니다. Default value: 4000 or 32767 (when MAX_STRING_SIZE=EXTENDED) |
'ORACLE 23ai' 카테고리의 다른 글
| Oracle Vector Index1-HNSW (2) | 2024.09.19 |
|---|---|
| ORACLE 23ai RAG(증강검색) 실습 (4) | 2024.09.19 |
| Oracle Embedding Model Load (1) | 2024.09.05 |
| RAG(검색 증강 생성)이란 (0) | 2024.08.26 |