OCI(Oracle Cloud Infrastructure)의 Compartment는 클라우드 리소스를 효율적으로 구성하고 관리하기 위한 핵심적인 기능입니다. 마치 폴더처럼 리소스를 논리적으로 그룹화하여 격리하고, IAM 정책을 통해 접근 권한을 세밀하게 제어할 수 있습니다.
Compartment를 사용하면 개발, 테스트, 운영 환경을 분리하여 보안을 강화하고, 프로젝트별 또는 부서별로 리소스를 관리하여 비용을 추적하고 예산을 효과적으로 운영할 수 있습니다. 계층 구조를 지원하여 조직 구조를 반영한 리소스 관리가 가능하며, 정책을 적용하여 특정 규칙을 준수하도록 강제할 수 있습니다.
OCI의 Compartment는 단순히 리소스를 묶는 것을 넘어, 클라우드 환경의 보안, 비용, 관리 효율성을 극대화하는 데 필수적인 요소입니다. 체계적인 Compartment 설계를 통해 클라우드 리소스를 안전하고 효율적으로 운영하고 관리할 수 있습니다.
OCI IAM
OCI IAM(Identity and Access Management)은 Oracle Cloud Infrastructure에서 누가 어떤 리소스에 액세스할 수 있는지 제어하는 서비스입니다. 간단히 말해, 클라우드 리소스에 대한 액세스 권한을 관리하는 '보안 관리자'라고 생각하시면 됩니다.
IAM 권한이란?
IAM 권한은 사용자, 그룹, 서비스 주체가 특정 리소스에 대해 수행할 수 있는 작업을 정의합니다. 예를 들어, 특정 사용자가 스토리지 버킷을 읽을 수 있지만 쓸 수는 없도록 설정하거나, 특정 그룹이 컴퓨트 인스턴스를 생성하고 삭제할 수 있도록 설정할 수 있습니다.
OCI Compartment 생성
Step 1.OCI 접속 후 홈 화면
Step 2. 우측상단 탐색메뉴(햄버거메뉴) 클릭
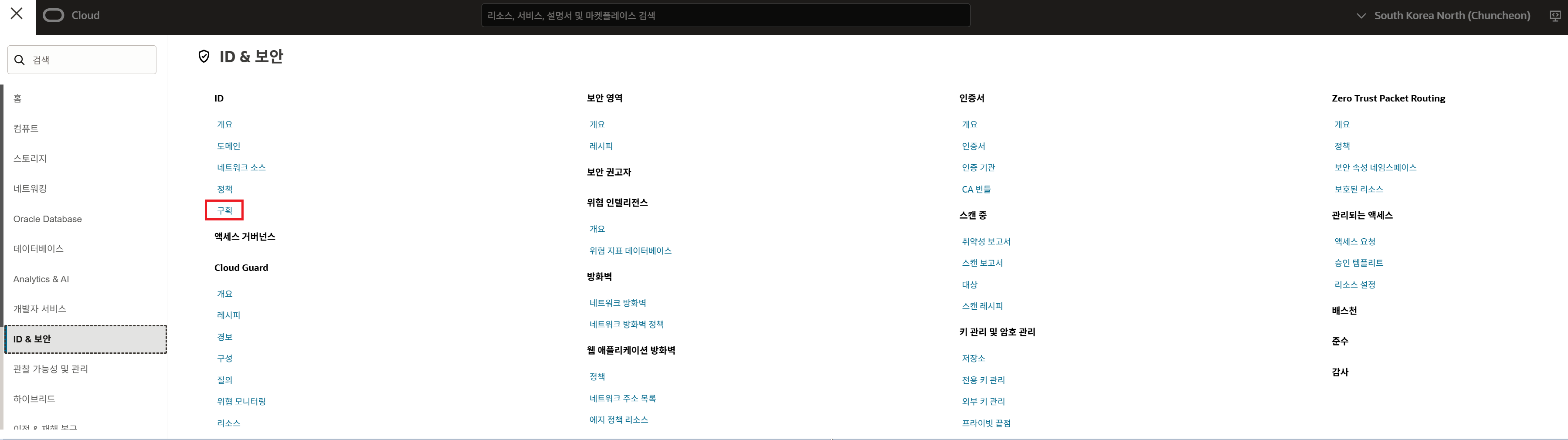
Step 3. ID & 보안 > 구획 클릭
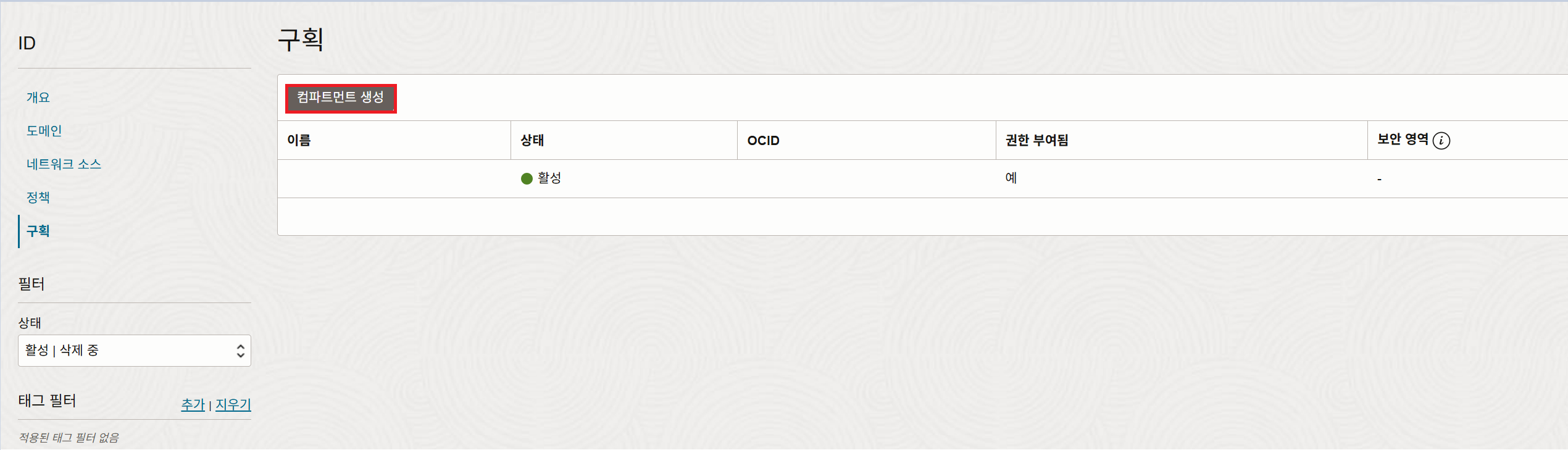
Step 4. 컴파트먼트 생성 클릭
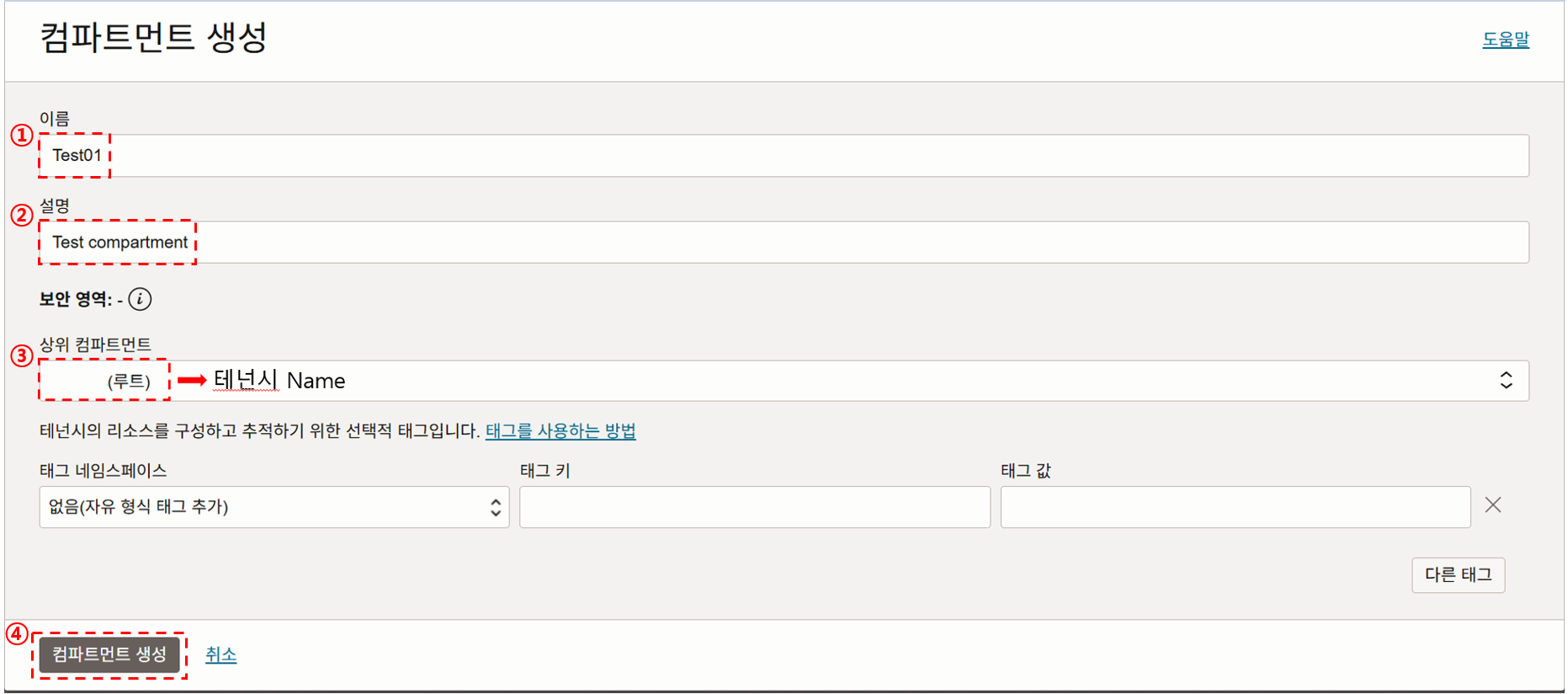
Step 5. 컴파트먼트 생성 이름, 설명을 입력하고 상위 컴파트먼트를 선택합니다. 상위 컴파트먼트는 초기 설정 시 테넌시Name으로 지정하시면 됩니다. 설정이 끝나면 컴파트먼트 생성을 클릭합니다.
Step 6. 컴파트먼트 생성 확인 Test01이라는 컴파트먼트가 생성된 것을 확인하실 수 있습니다.
Dataware 표준화 관리 업무를 진행하면서 사용자가 신청한 단어와 유사한 단어가 Dataware 사전에 등록되어 있는지 찾는 일이 간혹 발생했습니다. 예를들어 신청자가 "척도"라는 단어를 등록요청을 하면, 저는 척도라는 단어와 유사한 것들이 있는지 확인이 필요했습니다. 매번 네이버 사전과 Dataware를 넘나들며 단어를 찾느라 소모되는 시간이 너무 아쉽게 느껴져서 LLM의 도움을 받아서 간단한 코딩을 해보자라고 마음을 먹게되어 프로그램을 만들게 되었습니다.
1. Python에서 유의어 검색할 단어를 입력 2. 입력 받은 단어를 Ollama로 구축한 Local LLM에 유의어 추천 질의 3. LLM이 추천한 유의어들을 Dataware 사전 DB에 쿼리로 질의 (IN Union LIKE)
접속 환경 ini파일 정보
config.ini 파일 생성
[OracleDB]
# Optional: Set the path to your Oracle Instant Client directory
# Leave empty if PATH is already set correctly in your system environment
client_path = C:\instantclient-basic-windows.x64-23.7.0.25.01\instantclient_23_7
username =
password =
dsn =
table_name =
column_name =
[OllamaAPI]
url =
model = qwen2.5:7b
[AppSettings]
# Default number of synonyms to request from Ollama
default_synonyms = 10
Python 코드
import sys
import requests
import json
import cx_Oracle
import os
import configparser
import pprint
from PyQt5.QtWidgets import (QApplication, QWidget, QLabel, QLineEdit,
QPushButton, QVBoxLayout, QHBoxLayout,
QTextEdit, QListWidget, QMessageBox,
QTableWidget, QTableWidgetItem, QHeaderView,
QMenu, QAction) # Added QMenu, QAction
from PyQt5.QtCore import Qt, QPoint # Added QPoint
# --- Configuration Loading & Oracle Client Init ---
# ... (Keep this section exactly as before) ...
CONFIG_FILE = 'config.ini'
config = configparser.ConfigParser()
if not os.path.exists(CONFIG_FILE):
print(f"오류: 설정 파일 '{CONFIG_FILE}'을(를) 찾을 수 없습니다.")
print("스크립트와 동일한 디렉토리에 config.ini 파일을 생성해주세요.")
exit()
try:
config.read(CONFIG_FILE, encoding='utf-8')
oracle_client_path = config.get('OracleDB', 'client_path', fallback=None)
if oracle_client_path:
if sys.platform == "win32":
separator = ";"
else:
separator = ":"
current_path = os.environ.get('PATH', '')
if oracle_client_path not in current_path:
os.environ['PATH'] = oracle_client_path + separator + current_path
print(f"Oracle Client 경로 추가: {oracle_client_path}")
# else:
# print(f"Oracle Client 경로가 이미 PATH에 존재: {oracle_client_path}") # Less verbose
try:
# On modern cx_Oracle with PATH set, this might not strictly be needed
# but doesn't hurt if called correctly.
# Pass lib_dir only if required by your specific setup/version.
# cx_Oracle.init_oracle_client(lib_dir=oracle_client_path if oracle_client_path else None)
cx_Oracle.init_oracle_client()
print("Oracle Client 라이브러리 초기화 시도 완료")
except Exception as e:
# Make this non-fatal unless connection definitely fails later
print(f"경고: Oracle Client 라이브러리 초기화 중 오류 발생 (연결 시 문제될 수 있음): {e}")
# print("config.ini의 client_path 설정 또는 시스템 PATH 환경 변수를 확인하세요.")
# exit() # Don't exit here, let connect fail if needed
except configparser.Error as e:
print(f"설정 파일 '{CONFIG_FILE}' 읽기 오류: {e}")
exit()
except KeyError as e:
print(f"설정 파일 '{CONFIG_FILE}'에 필요한 키가 없습니다: {e}")
exit()
# --- Functions (get_synonyms, check_synonyms_in_db) ---
# ... (Keep these functions exactly as before) ...
def get_synonyms(word, config, num_synonyms=10):
"""requests를 사용하여 Ollama API를 호출하고 유의어 목록을 가져옵니다."""
try:
url = config.get('OllamaAPI', 'url')
model = config.get('OllamaAPI', 'model')
except (configparser.NoSectionError, configparser.NoOptionError) as e:
print(f"설정 파일 오류 (OllamaAPI 섹션): {e}")
return []
headers = {"Content-Type": "application/json"}
data = {
"model": model,
"prompt": f"'{word}'의 유의어 {num_synonyms}개를 추천해줘. 각각 쉼표로 구분해서 나열해줘. 반드시 한글사전에 있는 한글 단어들만 추천해줘.\
한문으로 된 것들은 유의어에서 제거해줘",
"stream": False
}
try:
# Increased timeout slightly
response = requests.post(url, headers=headers, data=json.dumps(data), timeout=45)
response.raise_for_status()
response_json = response.json()
synonym_string = response_json.get('response', '').strip()
# Fallback for potential other key names if needed
if not synonym_string:
synonym_string = response_json.get('generation', {}).get('completion', '').strip()
if not synonym_string:
print(f"Ollama API 응답에서 유의어 문자열을 찾을 수 없음. 응답: {response.text}")
return []
synonyms = [s.strip().replace("'", "") for s in synonym_string.split(",") if s.strip()]
return synonyms
except requests.exceptions.Timeout:
print(f"Ollama API 호출 시간 초과 ({url})")
return []
except requests.exceptions.RequestException as e:
print(f"Ollama API 호출 중 오류 발생 ({url}): {e}")
return []
except json.JSONDecodeError as e:
print(f"JSON 디코딩 오류: {e}. 응답: {response.text}")
return []
except KeyError:
# Less likely with .get() used above, but kept for safety
print(f"Ollama API 응답 형식 오류. 응답: {response.text}")
return []
def check_synonyms_in_db(synonyms, word, config, log_text_widget):
"""
유의어, 입력 단어, LIKE 검색 결과를 Oracle DB 테이블에 존재하는지 확인하고,
실행된 SQL 쿼리 로그를 반환합니다.
"""
connection = None
cursor = None
sql_logs = []
existing_synonyms = []
try:
username = config.get('OracleDB', 'username')
password = config.get('OracleDB', 'password')
dsn = config.get('OracleDB', 'dsn')
table_name = config.get('OracleDB', 'table_name')
column_name = config.get('OracleDB', 'column_name')
except (configparser.NoSectionError, configparser.NoOptionError) as e:
log_text_widget.append(f"[오류] 설정 파일 오류 (OracleDB 섹션): {e}")
return [], sql_logs
try:
log_text_widget.append(f"DB 연결 시도: {username}@{dsn}")
connection = cx_Oracle.connect(username, password, dsn)
cursor = connection.cursor()
log_text_widget.append("DB 연결 성공.")
search_terms = synonyms + [word] if word else synonyms # Avoid adding empty word if input was empty
# 1. IN 조건 검색
if search_terms:
sql_in = ""
bind_variables = {}
try:
placeholders = ", ".join(":" + str(i) for i in range(len(search_terms)))
# Using f-string safely as column/table names come from config
sql_in = f'SELECT "{column_name}" FROM {table_name} WHERE "{column_name}" IN ({placeholders})'
bind_variables = {str(i): term for i, term in enumerate(search_terms)}
sql_logs.append({"type": "IN", "sql": sql_in, "params": bind_variables})
cursor.execute(sql_in, bind_variables)
results_in = [row[0] for row in cursor.fetchall() if row[0] is not None]
existing_synonyms.extend(results_in)
log_text_widget.append(f"DB 결과 (IN): {results_in}")
except cx_Oracle.DatabaseError as db_err:
log_text_widget.append(f"[오류] DB IN 검색 오류: {db_err}")
if sql_in and (not sql_logs or sql_logs[-1]['sql'] != sql_in): # Log if not already logged
sql_logs.append({"type": "IN (Error)", "sql": sql_in, "params": bind_variables})
# 2. LIKE 조건 검색 (Only if word is not empty)
if word:
sql_like = ""
like_pattern = f"%{word}%"
try:
sql_like = f'SELECT "{column_name}" FROM {table_name} WHERE "{column_name}" LIKE :word_pattern'
sql_logs.append({"type": "LIKE", "sql": sql_like, "params": {"word_pattern": like_pattern}})
cursor.execute(sql_like, word_pattern=like_pattern)
results_like = [row[0] for row in cursor.fetchall() if row[0] is not None]
existing_synonyms.extend(results_like)
log_text_widget.append(f"DB 결과 (LIKE): {results_like}")
except cx_Oracle.DatabaseError as db_err:
log_text_widget.append(f"[오류] DB LIKE 검색 오류: {db_err}")
if sql_like and (not sql_logs or sql_logs[-1]['sql'] != sql_like):
sql_logs.append({"type": "LIKE (Error)", "sql": sql_like, "params": {"word_pattern": like_pattern}})
# 중복 제거 및 정렬
existing_synonyms = sorted(list(set(existing_synonyms)))
log_text_widget.append(f"DB 최종 결과 (중복 제거): {existing_synonyms}")
return existing_synonyms, sql_logs
except cx_Oracle.Error as error:
log_text_widget.append(f"[오류] Oracle DB 연결 또는 작업 오류: {error}")
# Attempt to return logs gathered so far
return [], sql_logs
finally:
if cursor:
cursor.close()
if connection:
connection.close()
log_text_widget.append("DB 연결 종료.")
# --- GUI Class ---
class SynonymFinderApp(QWidget):
def __init__(self, config):
super().__init__()
self.config = config
self.setWindowTitle("유의어 검색기")
self.setGeometry(100, 100, 900, 700)
self.initUI()
def initUI(self):
# --- Input ---
self.word_label = QLabel("단어 입력:")
self.word_input = QLineEdit()
self.word_input.returnPressed.connect(self.find_synonyms)
self.find_button = QPushButton("유의어 검색")
self.find_button.clicked.connect(self.find_synonyms)
input_layout = QHBoxLayout()
input_layout.addWidget(self.word_label)
input_layout.addWidget(self.word_input)
input_layout.addWidget(self.find_button)
# --- Results Lists ---
self.synonyms_label = QLabel("추천 유의어 (Ollama):")
self.synonyms_list = QListWidget()
self.synonyms_list.setSelectionMode(QListWidget.ExtendedSelection) # Allow multi-select
self.synonyms_list.setContextMenuPolicy(Qt.CustomContextMenu)
self.synonyms_list.customContextMenuRequested.connect(
lambda pos: self.show_list_context_menu(pos, self.synonyms_list)
)
self.db_synonyms_label = QLabel("DB에 존재하는 단어 (검색 결과):")
self.db_synonyms_list = QListWidget()
self.db_synonyms_list.setSelectionMode(QListWidget.ExtendedSelection) # Allow multi-select
self.db_synonyms_list.setContextMenuPolicy(Qt.CustomContextMenu)
self.db_synonyms_list.customContextMenuRequested.connect(
lambda pos: self.show_list_context_menu(pos, self.db_synonyms_list)
)
synonym_layout = QVBoxLayout()
synonym_layout.addWidget(self.synonyms_label)
synonym_layout.addWidget(self.synonyms_list)
db_synonym_layout = QVBoxLayout()
db_synonym_layout.addWidget(self.db_synonyms_label)
db_synonym_layout.addWidget(self.db_synonyms_list)
results_layout = QHBoxLayout()
results_layout.addLayout(synonym_layout)
results_layout.addLayout(db_synonym_layout)
# --- SQL Log Table ---
self.sql_log_label = QLabel("실행된 SQL 쿼리:")
self.sql_log_table = QTableWidget()
self.sql_log_table.setColumnCount(3)
self.sql_log_table.setHorizontalHeaderLabels(["Type", "SQL Query", "Parameters"])
self.sql_log_table.setEditTriggers(QTableWidget.NoEditTriggers)
# Allow selection of cells/rows
self.sql_log_table.setSelectionBehavior(QTableWidget.SelectItems) # Select individual cells
# self.sql_log_table.setSelectionBehavior(QTableWidget.SelectRows) # Or select whole rows
self.sql_log_table.setSelectionMode(QTableWidget.ExtendedSelection) # Allow multi-select
header = self.sql_log_table.horizontalHeader()
header.setSectionResizeMode(0, QHeaderView.ResizeToContents)
header.setSectionResizeMode(1, QHeaderView.Stretch)
header.setSectionResizeMode(2, QHeaderView.ResizeToContents) # Resize params initially
header.setStretchLastSection(False) # Prevent last section auto-stretch if params is narrow
self.sql_log_table.verticalHeader().setVisible(False)
self.sql_log_table.setMaximumHeight(180) # Slightly taller
self.sql_log_table.setContextMenuPolicy(Qt.CustomContextMenu)
self.sql_log_table.customContextMenuRequested.connect(self.show_table_context_menu)
# --- Main Log ---
self.log_label = QLabel("상세 로그:")
self.log_text = QTextEdit()
self.log_text.setReadOnly(True)
# QTextEdit already supports Ctrl+C and right-click copy by default
# --- Main Layout ---
main_layout = QVBoxLayout()
main_layout.addLayout(input_layout)
main_layout.addLayout(results_layout)
main_layout.addWidget(self.sql_log_label)
main_layout.addWidget(self.sql_log_table)
main_layout.addWidget(self.log_label)
main_layout.addWidget(self.log_text)
self.setLayout(main_layout)
# --- Context Menu Methods ---
def show_list_context_menu(self, position: QPoint, list_widget: QListWidget):
"""Shows context menu for QListWidget."""
menu = QMenu()
copy_action = QAction("복사 (Copy)", self)
selected_items = list_widget.selectedItems()
if selected_items:
copy_action.triggered.connect(lambda: self.copy_list_selection(list_widget))
else:
copy_action.setEnabled(False) # Disable if nothing selected
menu.addAction(copy_action)
# menu.exec_ -> Display menu at global position
menu.exec_(list_widget.mapToGlobal(position))
def copy_list_selection(self, list_widget: QListWidget):
"""Copies selected items' text from QListWidget to clipboard."""
selected_items = list_widget.selectedItems()
if selected_items:
text_to_copy = "\n".join([item.text() for item in selected_items])
clipboard = QApplication.clipboard()
clipboard.setText(text_to_copy)
self.log_text.append(f"[정보] {len(selected_items)}개 항목이 클립보드에 복사되었습니다.")
def show_table_context_menu(self, position: QPoint):
"""Shows context menu for QTableWidget."""
menu = QMenu()
copy_action = QAction("선택 셀 복사 (Copy Selected)", self)
selected_items = self.sql_log_table.selectedItems()
if selected_items:
# We can enhance this later to copy in TSV format if needed
copy_action.triggered.connect(self.copy_table_selection_simple)
# copy_action.triggered.connect(self.copy_table_selection_tsv) # Alternative
else:
copy_action.setEnabled(False)
menu.addAction(copy_action)
menu.exec_(self.sql_log_table.mapToGlobal(position))
def copy_table_selection_simple(self):
"""Copies text of selected table cells (newline separated) to clipboard."""
selected_items = self.sql_log_table.selectedItems()
if selected_items:
# Sort items by row, then column for predictable order
selected_items.sort(key=lambda item: (item.row(), item.column()))
text_to_copy = "\n".join([item.text() for item in selected_items])
clipboard = QApplication.clipboard()
clipboard.setText(text_to_copy)
self.log_text.append(f"[정보] {len(selected_items)}개 테이블 셀 내용이 클립보드에 복사되었습니다.")
# --- Optional: TSV Copy for Table (more complex) ---
def copy_table_selection_tsv(self):
"""Copies selected table cells as Tab Separated Values."""
selected_items = self.sql_log_table.selectedItems()
if not selected_items:
return
# Determine the bounds of the selection
min_row = min(item.row() for item in selected_items)
max_row = max(item.row() for item in selected_items)
min_col = min(item.column() for item in selected_items)
max_col = max(item.column() for item in selected_items)
# Create a grid (list of lists) to store the text
num_rows = max_row - min_row + 1
num_cols = max_col - min_col + 1
grid = [["" for _ in range(num_cols)] for _ in range(num_rows)]
# Populate the grid with selected item text
for item in selected_items:
row_index = item.row() - min_row
col_index = item.column() - min_col
grid[row_index][col_index] = item.text().replace('\n', ' ') # Replace newlines within a cell
# Join the grid into a TSV string
tsv_rows = ["\t".join(col for col in row) for row in grid]
text_to_copy = "\n".join(tsv_rows)
clipboard = QApplication.clipboard()
clipboard.setText(text_to_copy)
self.log_text.append(f"[정보] 테이블 선택 영역이 TSV 형식으로 클립보드에 복사되었습니다.")
# --- Other Methods ---
def add_sql_log_entry(self, query_info):
"""Adds a row to the SQL log table."""
table = self.sql_log_table
row_position = table.rowCount()
table.insertRow(row_position)
params_str = pprint.pformat(query_info.get("params", {}), indent=1, width=80)
type_item = QTableWidgetItem(query_info.get("type", "N/A"))
sql_item = QTableWidgetItem(query_info.get("sql", "N/A"))
params_item = QTableWidgetItem(params_str)
table.setItem(row_position, 0, type_item)
table.setItem(row_position, 1, sql_item)
table.setItem(row_position, 2, params_item)
# Auto-adjust row height might be needed if params_str is very long
# table.resizeRowToContents(row_position)
def find_synonyms(self):
word_to_find = self.word_input.text().strip()
# --- Clear previous results ---
self.log_text.clear()
self.synonyms_list.clear()
self.db_synonyms_list.clear()
self.sql_log_table.setRowCount(0)
# ---
if not word_to_find:
QMessageBox.warning(self, "입력 오류", "단어를 입력하세요.")
self.log_text.append("[오류] 단어가 입력되지 않았습니다.")
# Don't proceed if word is empty
return # Added return here
self.log_text.append(f"'{word_to_find}' 검색 시작...")
QApplication.processEvents()
try:
num_synonyms = self.config.getint('AppSettings', 'default_synonyms', fallback=10)
except (configparser.NoSectionError, configparser.NoOptionError, ValueError):
num_synonyms = 10
self.log_text.append("[경고] config.ini의 default_synonyms 설정 오류 또는 없음. 기본값 10 사용")
# 1. Get synonyms from Ollama
self.log_text.append(f"Ollama API 호출하여 유의어 검색 ({num_synonyms}개 요청)...")
QApplication.processEvents()
synonyms = get_synonyms(word_to_find, self.config, num_synonyms)
if not synonyms:
self.log_text.append("[정보] Ollama API에서 추천된 유의어를 찾지 못했거나 API 호출에 실패했습니다.")
else:
self.log_text.append(f"Ollama 추천 유의어: {synonyms}")
self.synonyms_list.addItems(synonyms)
QApplication.processEvents()
# 2. Check DB and get SQL logs
self.log_text.append("Oracle DB에서 단어 확인 중...")
QApplication.processEvents()
existing_db_words, executed_queries = check_synonyms_in_db(
synonyms, word_to_find, self.config, self.log_text
)
# Populate SQL Log Table
for query_info in executed_queries:
self.add_sql_log_entry(query_info)
# Adjust column widths after population if needed (especially params)
self.sql_log_table.resizeColumnToContents(2) # Resize Params column
# Re-apply stretch to SQL query column if resizing Params shrunk it too much
self.sql_log_table.horizontalHeader().setSectionResizeMode(1, QHeaderView.Stretch)
if existing_db_words:
self.db_synonyms_list.addItems(existing_db_words)
# else: # Logging handled within check_synonyms_in_db or based on executed_queries check
self.log_text.append("검색 완료.")
QApplication.processEvents()
# --- Main Execution ---
if __name__ == "__main__":
app = QApplication(sys.argv)
ex = SynonymFinderApp(config)
ex.show()
sys.exit(app.exec_())
실행파일로 프로그램화
1. Jupyter에서 작성한 Code 로컬로 다운로드
Jupyternotebook 환경에서 파이썬코드를 작성 및 테스트 하여, 로컬로 다운로드 후 실행파일로 변환하였습니다.
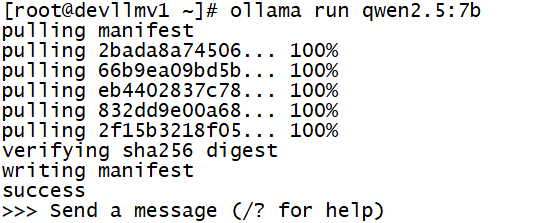
>>> Send a message (/? for help) 에 하고 싶은 질의를 작성 후 보냅니다.
>>> who are you?
>>> who are you?
I am Qwen, a large language model developed by Alibaba Cloud.
I'm here to assist with a wide range of tasks and provide information on various topics.
How can I help you today?
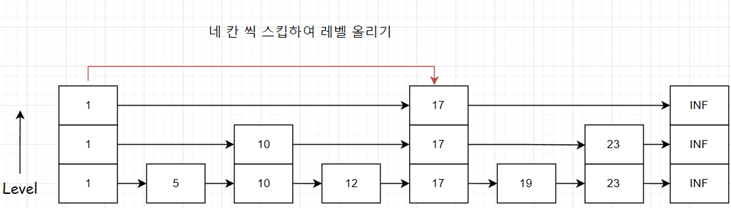
현재오라클에서지원하는벡터인덱스의종류는2가지입니다. 1.In-Memory Neighbor Graph = Hierarchical Navigable Small World (HNSW) 2.Neighbor Partition vector index = Inverted File Flat (IVF) index
HNSW는Hierarchical Navigable Small World의약자로여러알고리즘들의결합으로만들어져있습니다. 결합된알고리즘을분해해서살펴보면Small World 특성을바탕으로효율적인경로를탐색가능하게하는NSW(Navigable Small World)라는알고리즘에Skip List의개념을적용하여NSW 그래프를계층화한HNSW (Hierachical Navigable Small World) 알고리즘이만들어지게되었습니다.
Navigable Small World(NSW)를사용하면그래프의각벡터가세가지특성을기반으로여러다른벡터에연결되는근접그래프를구축하는것이목표입니다. 1.벡터사이의거리 2.삽입중검색과정에서각단계에서고려되는가장가까운벡터후보들의최대수 (EFCONSTRUCTION) 3.벡터당허용되는최대연결수(NEIGHBORS)
위의두임계값의조합이너무높으면밀집연결그래프가되어검색프로세스가느려질수있습니다.
반면, 해당임계값의조합이너무낮으면그래프가너무희소하거나연결이끊어져서검색중에특정벡터간의경로를찾기어려울수있습니다.
위의 베이컨 게임을 통해서 보았듯 우리는 수학적으로 6단계안에 관계가 형성되고 있고, 이러한 법칙을 바탕으로 Small World(작은세계)라는개념이탄생하게되었습니다. 스몰월드라는 네트워크 이론을 조금 더 살펴보겠습니다.
아래의 그래프처럼 모든네트웍은그연결방식에따라크게세가지로나눠질수있습니다. 일정한규칙에따라인접한곳과일정한숫자로만링크되는 'regular network'이있고, 무작위로서로연결되어있는'random network'이있습니다. 그리고 이둘의중간쯤에있는 Small-world가 있습니다. 스몰월드는 구성원의일부만이전혀엉뚱한곳으로연결되어있는네트워크입니다.
Small World Network를도식화한그래프에서 스몰월드의 상태를 알아보겠습니다. 가장왼쪽에있는그래프는모든Edge(간선,선)이고르게(Regular) 연결되어있는상태입니다. 가장오른쪽그래프는모든Edge가Random으로연결된상태입니다.
즉, 전체네트워크가거대하더라도일부의특정노드에의해서전체가서로가깝게연결될수있다는것을의미합니다.
Small world의이론적인특징을정리해보면다음과같습니다. 1.짧은평균경로길이: 베이컨게임에서보았듯Small world 네트워크에서네트워크내의임의의두노드사이의평균거리는매우짧습니다. 2.높은클러스터링(높은군집계수) : 이네트워크는노드들이지역적으로밀집된클러스터를형성하는경향이있습니다. 즉, 한노드의이웃노드들이서로연결되어있을가능성이큽니다. “내친구의친구도내친구일가능성이높다”라는상황으로나타날수있습니다. 3.긴거리연결: 비교적멀리떨어져있는노드들이특별한연결을통해서로직접연결되는것을의미합니다. 긴거리연결(long-range link)" 또는 "지름길(shortcut)로불리는이연결을통해전체의연결성을크게개선됩니다.
앞에서 NSW의 문제점인 Local minimum을 해결하기 위해 계층을 추가하여 HNSW (Hierarchical Navigable Small World)를 만들었습니다. HNSW(Hierachical Navigable Small World)는근사최근접이웃탐색(Approximate Nearest Neighbor Search)을위해사용되는알고리즘으로NSW에문제점인로컬미니멈을해결하기위해 skip list의개념을적용하여, NSW 그래프를계층화한알고리즘입니다. 계층을 효율적으로 나누기 위해서 Skip list 개념을 사용하는데 잠깐 알아보고 HNSW로 넘어가겠습니다.
참고 - 체크: 오라클에서는HNSW인덱스가있는테이블은DML문이안됩니다. ORA-51928: 인메모리인접그래프벡터인덱스가있는테이블에서는 DML(데이터조작어)이지원되지않습니다. 오라클DB에서는DML문이되지않으므로확률스킵리스트의삽입및삭제의이점이작습니다.
하지만, INDEX를생성시에삽입의이점을받을수있고, EFCONSTRUCTION 파라미터를통해조정할수있습니다. 인덱스를스토리지가아닌메모리공간에생성하여사용하기때문에DML문이제한되지않을까라는생각이듭니다. 그럼에도불구하고확률스킵리스트를채택한이유는HNSW 알고리즘에서확률형스킵리스트가탐색효율성을높이는데효과가있고, 메모리의효율성또한높일수있기때문이라고생각이듭니다.
- EFCONSTRUCTION:삽입중검색의각단계에서고려되는가장가까운벡터후보의최대개수
HNSW(Hierarchical Navigable Small World)
여러 복잡한 알고리즘들을 알아본 끝에 앞에 알고리즘들의 결합인 HNSW에 대해 알아보겠습니다. 위에서 설명한 바와 같이 HNSW(Hierachical Navigable Small World)는근사최근접이웃탐색(Approximate Nearest Neighbor Search)을위해사용되는알고리즘으로NSW에문제점인로컬미니멈을해결하기위해 skip list의개념을적용하여, NSW 그래프를계층화한알고리즘입니다.
ORACLE Vector Index를 공부하면서 여러 알고리즘들을 접하였는데, 이해가 쉽지않았습니다. 이곳저곳을 찾아가며 정보를 얻은것들을 바탕으로 작성했는데, 오라클에서 추구하는 HNSW와 조금 차이가 있을 수 있습니다. ORACLE Document에서는 간략하게만 설명이 나와있어서 추가적인 정보를 붙여서 정리했는데 도움이 되었으면 좋겠습니다.
앞선 글에서 RAG에 대해 DBA의 관점으로 간략하게 설명을 했습니다. (RAG(검색 증강 생성)이란 글 참고) ORACLE DB에서 RAG를 사용하는 방법에 대해 알아보겠습니다. 제가 테스트 한 버전은 23AI Free 버전이므로 추후 EE버전에서는 내용이 달라질 수 있습니다.
create table dre.rag_test as
select embed_id,embed_data,to_vector(embed_vector) as embed_vector
FROM (select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대법원선고중요판결요지_240829.pdf')) a (file_name) ) dc
CROSS JOIN TABLE (
dbms_vector_chain.utl_to_embeddings(
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(dc.DOC_CONTENT_BLOB)
,json('{"by":"characters","max":"250","split":"none","normalize":"all","LANGUAGE":"KOREAN"}')),
json('{"provider":"database", "model":"ONN.DISTILUSE_BASE_MULTILINGUAL_CASED_V2"}'))) t
CROSS JOIN JSON_TABLE(t.column_value, '$[*]' COLUMNS (embed_id NUMBER PATH '$.embed_id', embed_data VARCHAR2(1000) PATH '$.embed_data', embed_vector clob PATH '$.embed_vector')) AS et;
declare
input clob;
params clob;
output clob;
begin
utl_http.set_body_charset('UTF-8');
input := '안녕 exaone3.0:8b 모델에 대해 설명해줘';
params := '
{
"provider": "OpenAI",
"credential_name": "EXAONE_CRED",
"url": "http://172.17.12.116:9301/v1/chat/completions",
"model": "exaone3.0:8b",
"context_length" : 2048
}';
output := dbms_vector_chain.utl_to_generate_text(input, json(params));
dbms_output.put_line(output);
if output is not null then
dbms_lob.freetemporary(output);
end if;
exception
when OTHERS THEN
DBMS_OUTPUT.PUT_LINE (SQLERRM);
DBMS_OUTPUT.PUT_LINE (SQLCODE);
end;
/
#질의 결과
-------------------------[Start Time: 2024/09/19 15:24:39]-------------------------
SQL> 안녕하세요! LG AI 연구원에서 개발한 EXO(EXpert Operating System) 3.0 기반의 8B 모델, EXAONE 3.0에 대해 설명해드릴게요.
### 주요 특징 및 장점:
1. **고성능 언어 이해 능력**:
- 한국어와 영어를 포함해 다양한 자연어 처리 작업에서 우수한 성능을 자랑합니다.
2. **초거대 AI 모델 기반**:
- 8x Nvidia A100 GPU로 학습되었으며, 약 6TFLOPS의 연산 능력을 가집니다. 이는 기존 초거대 인공지능 대비 효율적이고 강력한 계산력입니다.
3. **전문 지식 통합**:
- 방대한 양의 전문 문서 데이터를 바탕으로 다양한 산업의 최신 정보와 전문 지식을 습득할 수 있습니다.
4. **생성적 AI 능력**:
- 창작 활동 (예: 소설 작성, 음악 작곡 등)에도 뛰어난 성능을 보입니다. 이는 모델이 단순히 데이터를 분석하는데 그치지 않고 새로운 지식과 콘텐츠를 생성해 낼 수 있음을 의미합니다.
5. **한국어 특화 학습 모델**:
- 한국어에 최적화된 언어 모델로 감정 분석, 번역 작업 등에서도 우수한 성과를 보이며, 멀티모달 데이터 처리 기능이 강화되어 이미지 인식까지 확장할 수 있습니다.
6. **데이터 학습 윤리 및 프라이버시 준수**:
- 개인정보 보호 규정과 윤리적인 AI 개발 가이드라인을 철저히 준수하여 안전하게 활용 가능합니다.
### 결론적으로,
EXAONE 3.0은 여러 산업의 전문 작업 지원, 창의성 발휘 등 다양한 방면에서 효과적으로 사용될 수 있는 차세대 인공지능 모델입니다. 여러분께서 필요로 하시는 특정 분야나 적용 사례가 있다면 더 구체적인 설명도 가능하니 말씀해 주세요!
CREATE OR REPLACE FUNCTION DRE.fn_rag_test(p_user_question VARCHAR2) RETURN CLOB
AUTHID DEFINER
IS
v_model_params JSON ;
v_user_question_vec vector;
v_prompt varchar2(1000);
v_sys_instruction varchar2(1000);
v_message clob;
v_user_question varchar2(1000);
v_k_stop_count number := 1;
output clob;
BEGIN
v_model_params := JSON('
{
"provider":"OpenAI",
"credential_name":"EXAONE_CRED",
"url": "http://172.17.12.116:9301/v1/chat/completions",
"model": "exaone3.0:8b",
"context_length" : 2048
}') ;
-- JSON형식에서 질의내용만 추출 :
v_sys_instruction := 'Please answer with only facts based on the searched content.답변은 한국어로 번역해서 대답해줘';
v_user_question := p_user_question ;
-- 질의내용에 대한 쿼리 벡터 생성
SELECT TO_VECTOR(vector_embedding(onn.distiluse_base_multilingual_cased_v2 USING v_user_question as data)) as embedding into v_user_question_vec ;
-- 텍스트 유사도 검색 (Multi-Vector Similarity Search)
select json_arrayagg(
json_object('EMBED_ID' is EMBED_ID, 'EMBED_DATA' is EMBED_DATA)
returning CLOB) into v_message
from (
SELECT EMBED_ID ,
EMBED_DATA
FROM DRE.rag_test
ORDER BY VECTOR_DISTANCE(EMBED_VECTOR , v_user_question_vec, COSINE)
FETCH FIRST v_k_stop_count ROWS ONLY WITH TARGET ACCURACY 90
);
-- 프롬프트생성
v_prompt := '
<s>[INST] {system_instruction}.
Search Data:
{insert_search_data_here}
User Query:
{user_query}
Provide a detailed response based on the search data above. [/INST]
';
v_prompt := replace(replace(replace(v_prompt,'system_instruction',v_sys_instruction),'{insert_search_data_here}', v_message),'{user_query}',v_user_question);
-- Return the substring of the CLOB within the size limit
-- output := DBMS_LOB.SUBSTR(v_prompt, 4000, 1);
utl_http.set_body_charset('UTF-8');
output := dbms_vector_chain.utl_to_generate_text(v_prompt, v_model_params);
RETURN output;
END;
/
7. RAG 실행
위에서 만들 RAG 함수를 사용하여 Ollama 서버에 증강검색을 합니다.
DECLARE
p_user_question CLOB := '마약류관리에관한법률위반(향정) 를 파기환송한 이유에 대해 알려줘'; -- 여기에 p_user_question의 값을 직접 입력
output CLOB;
BEGIN
output := DRE.fn_rag_test(p_user_question );
DBMS_OUTPUT.PUT_LINE('Output: ' || output);
END;
/
-------------------------[Start Time: 2024/09/12 07:46:11]-------------------------
SQL> Output: 마약류관리에 관한 법률 위반(향정) 사건을 파기환송한 이유는 피고인 및 그와 공범관계에 있던 A의 사례로 볼 수 있습니다. 주된 쟁점은 검사 또는 사법경찰관 작성 피의자신문조서의 증거능력이었습니다.
아래는 이를 근거로 한 상세 설명입니다:
1. **검사 또는 사법경찰관 작성 피의자신문조서**: 피고인과 공범인 A에 대한 경우, 이들 작성한 신문조서가 법적으로 증거 능력을 가지는지 여부가 중요한 쟁점으로 다뤄졌습니다.
2. ***형사소송법 제312조***: 형사소송법 제312조는 검사 또는 경찰 작성의 피의자신문조서에 대한 규정을 담고 있으며, 이를 통하여 피고인이 진술거부권과 변호인 조력을 받을 권리를 보호하면서도 실질적인 진술 내용이 신뢰할 만한지 평가합니다.
- 동 조항에 따르면 피의자나 피고인이 경찰이나 검찰 조사 과정에서 자백하거나 진술한 내용이 진정한 것인지를 판단하기 위해 몇 가지 요건들(예: 피고인의 자발성, 임의성)을 충족해야 합니다.
3. **원심 판결**: 원심(아래 단계 법원)은 이러한 형사 소송법 규정과 그 해석에 따라 본 사건에서 검사 또는 사법경찰관 작성 피의자신문조서를 적법하게 인정하고 유죄판결을 내렸습니다. 그러나 위에서 언급된 요건들이 충분히 충족되지 않았다고 판단하여 사후 증거능력이 문제가 되었고 이에 대한 상고가 제기됐습니다.
4. **대법원 판결**: 대법원은 원심의 판단이 부족함을 지적하며 사건을 상급심으로 돌려보냈습니다(즉, 파기환송). 대법원은 보다 면밀한 검토를 통해 실제 조사 과정에서 진술 강요 여부와 자발성 등에 대해 엄격히 재검토할 필요성이 있다고 보았던 것입니다.
- 또한, 구체적인 사실관계 분석 및 관련 법령 적용에 있어서 추가 조사가 요구된 상황이었기 때문으로 추정됩니다.
따라서, 마약류관리에 관한 법률위반(향정)을 기소한 본 사건에서는 법원들 간 해석 차이와 이에 따른 심리 부족 등의 문제로 인해 최종 판단은 상급심인 대법원의 재검토 아래 다시 진행되게 된 것입니다.
마치며
테스트를 하면서 신기하다는 느낌은 받았지만, RAG를 활용하여 제품을 만들어서 활용하는 모습은 시간이 조금 걸릴것 같다라는 생각을 했습니다. 하지만, AI기술의 발전 속도를 보면 머지않아 우리 실생활에 빠질 수 없는 중요한 요소가 될 것이라고 생각이 듭니다.
ORACLE DB에서 AI를 활용하여 무엇을 할 수 있다는게 신기했습니다. 제가 테스트한 ORACLE 23AI FREE버전은 23.5인데 dbms_vector_chain.utl_to_generate_text 라는 함수를 사용하여 LLM쪽으로 질의를 하였습니다. 문제는 dbms_vector_chain.utl_to_generate_text 이 함수가 처음에는 VARCHAR2(4000)의 제한이 있었는데 현재 벡터서치 가이드에서는 CLOB로 변경된 것으로 보입니다. 가이드에서처럼 Ollama Provider제공과 위 함수의 clob 지원이 되는 새로운 버전이 빨리 나왔으면 하는 바램입니다.
앞에 글들을 따라 오셨다면 ORACLE23 ai설치와 OML4Py 설치를 끝내셨을겁니다. 사전 학습된 오픈 소스 임베딩 모델이나 자체 임베딩 모델을 사용하여 Oracle Database 외부에서 벡터 임베딩을 생성할 수 있지만, Open Neural Network Exchange(ONNX) 표준과 호환되는 경우 해당 모델을 Oracle Database로 직접 가져올 수도 있습니다. 오라클에서 제공하는 머신러닝용 패키지인 OML4Py를 사용하여 ONNX 형식에 Embedding Model을 ORACLE DB에 로딩하는 방법을 알아보겠습니다.
Model Load
1.모델을 관리할 스키마 생성
필요에 따라 모델을 관리할 스키마를 생성합니다. 저는 데이터 영역과 모델영역에 서비스 구분을 위해 ONN이라는 스키마를 생성하여 진행하겠습니다.
cd $ORACLE_HOME/oml4py/server
sqlplus / as sysdba
alter session set container=freepdb1;
CREATE TABLESPACE TS_ONN DATAFILE '/u01/oracle/FREE/FREEPDB1/ts_onn_1.dbf' SIZE 100M AUTOEXTEND ON NEXT 100M MAXSIZE 30G EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
@pyquser.sql ONN TS_ONN TEMP unlimited pyqadmin
참고: 23ai부터 create tablespace 시 bigfile이 default값입니다. Starting with Oracle Database 23ai, BIGFILE functionality is the default for SYSAUX, SYSTEM, and USER tablespaces.
2.DB에 Directory object 생성
OS에 있는 Model을 DB안으로 가져오기 위해 Directory Object를 생성합니다.
sqlplus / as sysdba
alter session set container=freepdb1;
SQL> alter session set container=freepdb1;
grant read,write on directory MODEL_DIR to ONN;
3.사전구성된 Model 확인
오라클에서 테스트한 모델을 확인 할 수 있습니다. Free버전이므로 아래에 모델 중 한국어 지원이 되는 'sentence-transformers/distiluse-base-multilingual-cased-v2' 모델을 사용하였습니다.
#명령어
python3
>>> from oml.utils import EmbeddingModel
EmbeddingModelConfig.show_preconfigured()
폐쇄망의 경우 파일을 직접 받아서 서버에 업로드 해야합니다. 업로드 위치는 생성한 디렉토리로 해주세요.
#명령어
python3
>>> from oml.utils import EmbeddingModel
>>> em = EmbeddingModel(model_name="sentence-transformers/distiluse-base-multilingual-cased-v2")
>>> em.export2file("distiluse-base-multilingual-cased-v2",output_dir="./")
/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/transformers/models/distilbert/modeling_distilbert.py:215: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
mask, torch.tensor(torch.finfo(scores.dtype).min)
5.Embedding Model Load
임베딩 모델을 DB에 로드 합니다.
#명령어
sqlplus / as sysdba
alter session set container=freepdb1;
#모델디렉토리:MODEL_DIR
#모델파일:distiluse-base-multilingual-cased-v2.onnx
#스키마.모델명(원하는대로 입력가능):ONN.distiluse_base_multilingual_cased_v2
begin
DBMS_VECTOR.LOAD_ONNX_MODEL('MODEL_DIR','distiluse-base-multilingual-cased-v2.onnx','ONN.distiluse_base_multilingual_cased_v2',
JSON('{"function" : "embedding", "embeddingOutput" : "embedding", "input":{"input": ["DATA"]}}'));
end;
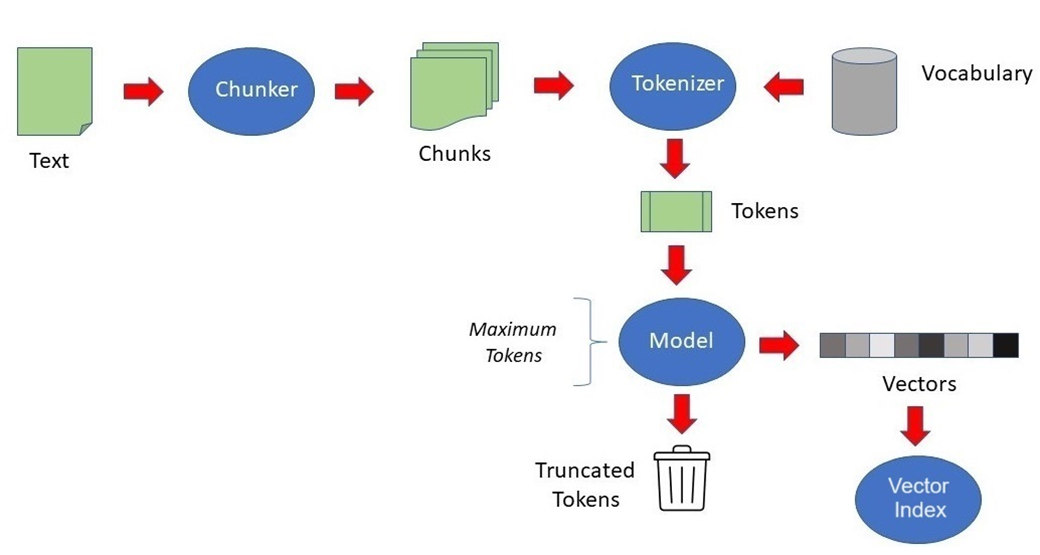
오라클의 23ai Document 를 보고 정리한 내용입니다. ORACLE Document URL :https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/index.html 23ai 공개 이후 AI에 대해 관심이 생겨 여러 자료들을 찾아보며 RAG(증강검색생성)까지 진행을 해봤습니다. RAG를 할수록 원본 데이터의 품질이 중요하다고 느껴졌습니다. 아직 청킹을 잘 하는 방법에 대해서는 이것저것 테스트를 해보고 있습니다. 우선 LLM과 RAG를 하기 전 데이터를 청킹하고 모델을 통해 임베딩을 하는 과정을 소개하려고 합니다.
Oracle AI Vector Search는 Oracle Database 내부 또는 외부의 비정형 데이터에서 벡터 임베딩을 자동으로 생성하는 Vector Utilities(SQL 및 PL/SQL 도구)를 제공합니다. 벡터 임베딩 모델은 단어, 문장 또는 단락과 같은 데이터의 각 요소에 숫자 값을 할당하여 임베딩을 만듭니다. 데이터베이스내에서임베딩을생성하려면 ONNX 형식의벡터임베딩모델을가져와사용할수있습니다. 데이터베이스외부에서임베딩을생성하려면타사 REST API를호출하여타사벡터임베딩모델에액세스할수있습니다.
select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ;
텍스트로변환된데이터를청킹(UTL_TO_CHUNKS)
select t.*
FROM (select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ) dc
CROSS JOIN TABLE (
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(dc.DOC_CONTENT_BLOB)
,json('{"by":"characters","max":"3000","split":"none","normalize":"all","LANGUAGE":"KOREAN"}'))) t;
parameter :
BY:CHARACTERS(문자 수를 세어 나눔)
MAX:3000(각 청크의 최대 크기에 대한 제한을 지정합니다. 최대 크기 제한에 도달하면 데이터를 분할합니다.)
SPLIT:NONE(입력 텍스트가 최대 크기 제한에 도달했을 때 분할할 위치를 지정합니다. NONE은 한계 에서 분할하는 의미)
NORMALIZE:all(문서를 텍스트로 변환할 때 발생할 수 있는 문제(여러 개의 연속된 공백 및 smart quotes(굽은 따옴표(‘’,“”)) 등)를 자동으로 전처리하거나 후처리합니다. all=유니코드 구두점을 standard single-byte로 정규화합니다.)
LANGUAGE:KOREAN(언어는 한국어)
각 청크에 벡터 임베딩을 생성(UTL_TO_EMBEDDINGS)
select t.*
FROM (select
dbms_vector_chain.utl_to_text(TO_BLOB(bfilename('DOC_DIR',a.file_name))) AS DOC_content_blob
from (values('대한민국 헌법.pdf')) a (file_name) ) dc
CROSS JOIN TABLE (
dbms_vector_chain.utl_to_embeddings(
dbms_vector_chain.utl_to_chunks(
dbms_vector_chain.utl_to_text(dc.DOC_CONTENT_BLOB)
,json('{"by":"characters","max":"3000","split":"none","normalize":"all","LANGUAGE":"KOREAN"}')),
json('{"provider":"database", "model":"ONN.DISTILUSE_BASE_MULTILINGUAL_CASED_V2"}'))) t
CROSS JOIN JSON_TABLE(t.column_value, '$[*]' COLUMNS ( embed_vector CLOB PATH '$.embed_vector')) AS et;
[표:제공되는체인가능한유틸리티함수]
기능
설명
입력및반환값
UTL_TO_TEXT()
데이터(예: Word, HTML 또는 PDF 문서)를 일반 텍스트로 변환합니다.
CLOB 또는 BLOB로 입력을 허용합니다. 문서의 일반 텍스트 버전을 CLOB로 반환합니다
UTL_TO_CHUNKS()
데이터를 청크로 변환합니다.
입력을 일반 텍스트(CLOB 또는VARCHAR2)로 허용합니다. 데이터를 분할하여 청크 배열(CLOB)을 반환합니다.
데이터 분할 모드를 지정합니다. 즉, 문자, 단어 또는 어휘 토큰의 수를 세어 분할합니다. 유효한 값 : ·BY CHARACTERS(또는 BY CHARS): 문자 수를 세어 나눕니다. ·BY WORDS: 단어의 개수를 세어 나눕니다. 단어는 알파벳 문자 시퀀스, 숫자 시퀀스, 개별 구두점 또는 기호로 정의됩니다. 공백 단어 경계가 없는 분할 언어(예: 중국어, 일본어 또는 태국어)의 경우 각 모국어 문자는 단어(즉, 유니그램)로 간주됩니다. ·BY VOCABULARY: 어휘 토큰의 개수를 세어 나눕니다. 어휘 토큰은 임베딩 모델이 사용하는 토크나이저의 어휘로 인식되는 단어 또는 단어 조각입니다. VECTOR_CHUNKShelper API 사용하여 어휘 파일을 로드할 수 있습니다 DBMS_VECTOR_CHAIN.CREATE_VOCABULARY. 참고 : 정확한 결과를 얻으려면 선택한 모델이 청크에 사용된 어휘 파일과 일치하는지 확인하십시오. 어휘 파일을 사용하지 않는 경우 입력 길이가 모델의 토큰 제한 내에서 정의되었는지 확인하십시오. 기본값 :BY WORDS
MAX
각 청크의 최대 크기에 대한 제한을 지정합니다. 이 설정은 더 큰 텍스트에서 최대 제한이 발생하는 고정된 지점에서 입력 텍스트를 분할합니다. 단위는 모드 MAX에 해당합니다 BY. 즉, 특정 수의 문자, 단어, 숫자, 구두점 또는 어휘 토큰의 최대 크기 제한에 도달하면 데이터를 분할합니다. 유효한 값 : ·BY CHARACTERS: 50 to 4000 characters ·BY WORDS: 10 to 1000 words ·BY VOCABULARY: 10 to 1000 tokens 기본값 :MAX 100
SPLIT [BY]
입력 텍스트가 최대 크기 제한에 도달했을 때 분할할 위치를 지정합니다. 이는 청크에 대한 적절한 경계를 정의하여 관련 데이터를 함께 유지하는 데 도움이 됩니다. Valid values: 1.NONE: MAX문자, 단어 또는 어휘 토큰의 한계 에서 분할됩니다 . 2.NEWLINE, BLANKLINE, and SPACE: MAX 값 이전의 마지막 분할 문자에서 분할되는 단일 분할 문자 조건입니다. NEWLINE을 사용하여 텍스트 행의 끝에서 분할합니다. BLANKLINE을 사용하여 공백 행의 끝(예: 두 줄의 새 행)에서 분할합니다. SPACE를 사용하여 공백 행의 끝에서 분할합니다. ·RECURSIVELY: 이것은 문자(또는 시퀀스)의 순서대로 나열된 목록을 사용하여 입력된 텍스트를 깨는 다중 분할 문자 조건입니다. RASCERIESS는 다음 순서로 블랭크 라인, 새 라인, 스페이스, 없음으로 미리 정의됩니다: 1. 입력 텍스트가 MAX 값보다 크면 첫 번째 분할 문자로 분할합니다. 2. 실패할 경우 두 번째 분할 문자로 분할합니다. 3. 등등. 4. 분할 문자가 없는 경우 텍스트에 표시되는 곳마다 MAX로 분할합니다.
·SENTENCE: 문장 경계에서 입력된 텍스트를 끊는 문장 끝 분할 조건입니다. 이 조건은 입력 언어의 문장 문장부호에 대한 지식과 문맥 규칙을 사용하여 문장 경계를 자동으로 결정합니다. 이 언어별 조건은 대부분 EOS(End-of-Sentence) 문장부호와 일반적인 약어에 의존합니다. 문맥 규칙은 단어 정보를 기반으로 하므로 이 조건은 텍스트를 단어 또는 어휘로 분할할 때만 유효합니다(not by characters).
Note: 이 조건은 BY WORD 및 MAX 설정을 따르므로 경우에 따라 정확한 문장 경계를 결정할 수 없습니다. 예를 들어, 문장이 MAX 값보다 크면 MAX에서 문장을 분할합니다. 마찬가지로 MAX 한계 내에 맞는 경우에만 텍스트에 여러 문장을 포함합니다.
·CUSTOM: 사용자 정의 분할 문자 목록에 따라 분할합니다. 각각 최대 10개의 길이로 최대 16개의 분할 문자 문자열로 사용자 정의 시퀀스를 제공할 수 있습니다. 다음과 같이 유효한 텍스트 리터럴을 제공합니다: tab(\t), newline(\n), linefeed (\r)에 대해서만 시퀀스를 생략할 수 있습니다. Default value: RECURSIVELY
OVERLAP
청크가 포함해야 할 이전 텍스트의 양(양의 정수 리터럴 또는 0)을 지정합니다. 이는 이전 청크 텍스트의 일부 양을 포함하여 관련 텍스트(예: 문장)를 논리적으로 분할하는 데 도움이 됩니다. 중복의 양은 청크의 최대 크기를 측정하는 방법(문자, 단어 또는 어휘 토큰)에 따라 달라집니다. 중복은 지정된 SPLITE 조건(예를 들어 NEWLINE에서)에서 시작됩니다. Valid value: 5% to 20% of MAX Default value: 0
LANGUAGE
입력 데이터의 언어를 지정합니다. 이 절은 특히 텍스트에 다른 언어로 다르게 해석될 수 있는 특정 문자(예: 구두점 또는 약어)가 포함되어 있는 경우 중요합니다. Valid value: Oracle Database Globalization Support Guide에 나열된 모든 NLS 지원 언어 이름 또는 언어 약어. 공백이 있는 모든 언어 이름에는 반드시 double quotation(")을 사용해야합니다. For example: LANGUAGE "simplified chinese"
한 단어 언어 이름의(one-word language names)경우 quotation 표시가 필요하지 않습니다. For example: LANGUAGE american
Note: DBMS_VECTOR_CHAIN.CREATE_LANG_DATA chunker helper API를 사용하여 지정된 언어에 대해 언어별 데이터(약어 tokens)를 데이터베이스에 로드할 수 있습니다. Default value: NLS_LANGUAGE from session
NORMALIZE
문서를 텍스트로 변환할 때 발생할 수 있는 문제(여러 개의 연속된 공백 및 smart quotes(굽은 따옴표(‘’, “”)) 등)를 자동으로 전처리하거나 후처리합니다. 오라클은 이 모드를 사용하여 품질이 좋은 청크를 추출하는 것을 권장합니다. Valid values: ·NONE: 정규화를 지정하지 않습니다. ·ALL: 공통 다중 바이트(유니코드) 구두점을 standard single-byte로 정규화합니다. ·PUNCTUATION: smart quotes, smart hyphens및 기타 단일 바이트 구두점과 동일한 멀티 바이트를 포함합니다. For example: o2018u 'map to 0027' o2019u 'map to 0027' o201Bu 'map to 0027' ·WHITESPACE: 불필요한 문자를 제거하여 공백을 최소화합니다. For example, blanklines은 유지하되, 추가로 newlines,spaces,tabs 는 제거합니다: " \n \n " => "\n\n" ·WIDECHAR: 넓고 다중 바이트인 숫자와 (az) 문자를 단일 바이트로 정규화합니다. 0-9 및 a-z A-Z로 된 다중 바이트이며 , ZH/JA 형식 텍스트로 표시할 수 있습니다. Note: 쉼표로 구분된 여백(WHITESPACE), 구두점(PUNCTUATION), and WIDECHAR 괄호 목록(WIDECHAR in parentheses)을 반드시 지정해야합니다. Default value: None
EXTENDED
MAX_STRING_SIZE 매개 변수를 EXTED로 설정할 필요 없이 VARCHAR2 문자열의 출력 제한을 32767bytes로 늘립니다. Default value: 4000 or 32767 (when MAX_STRING_SIZE=EXTENDED)
AI 관련 테스트를 하다보면 오픈소스 라이브러리들을 많이 사용하게 되는데, 폐쇄망 서버에서는 제약사항들이 너무 많았습니다. 인터넷 환경의 경우 pip 를 통해서 설치가 매우 간단했는데, 사용할 수 없다보니 인터넷환경 테스트 로컬 테스트 서버를 구축하고 거기서 패키지들을 복사해서 서버에 옮긴 후 작업을 했습니다..
패키지별로 종속성이 얽혀있다보니 설치 순서가 중요하므로 설치 순서에 신경쓰면서 작업하세요.
다른 패키지들은 전부 설치가 되었는데 numpy-1.26.4 버전의 설치가 되지않아서 어쩔수 없이 정상적으로 설치된 서버 tar로가져와서작업했습니다. numpy 설치 시 버전에 대한 업그레이드가 진행되지 않았습니다. 설치 에러는 아래와 같습니다.
트러블슈팅 -ValueError: numpy.dtype size changed발생시=> oml4py 서버에 numpy==1.26.4 강제 업그레이드로 설치. 폐쇄망에서는 --target --upgrade to force 명령어불가로설치된서버 oml4py디렉토리를 tar 가져옴 >>> res = oml.do_eval(func='TEST') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "oml/embed/eval.py", line 112, in oml.embed.eval.do_eval File "oml/embed/eval1.py", line 257, in oml.embed.eval1.__eval File "/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/oracledb/cursor.py", line 701, in execute impl.execute(self) File "src/oracledb/impl/thick/cursor.pyx", line 306, in oracledb.thick_impl.ThickCursorImpl.execute File "src/oracledb/impl/thick/utils.pyx", line 456, in oracledb.thick_impl._raise_from_odpi File "src/oracledb/impl/thick/utils.pyx", line 446, in oracledb.thick_impl._raise_from_info oracledb.exceptions.DatabaseError: ORA-20000: PyQuery error ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject ORA-06512: "PYQSYS.PYQ$EVALIMPL_IN",77행 ORA-06512: "PYQSYS.PYQ$EVALIMPL_IN",74행
가상화서버 cd /opt/oracle/product/23ai/dbhomeFree tar -cvf oml4py.par oml4py
설치중인서버 cd /opt/oracle/product/23ai/dbhomeFree rm -rf oml4py tar -xvf oml4py.tar
머신러닝에서 가장 인기 있는 언어는 Python입니다. 파이썬은 풍부한 라이브러리(TensorFlow, Keras, Scikit-learn)와 단순한 문법 덕분에 머신러닝 연구와 개발에 매우 적합한 언어로 인식되고 있습니다.
오라클 DB에서 파이썬을 사용하기 위한 API 인 OML4Py에 대해 간단하게 설명하겠습니다.
OML4Py(Oracle Machine Learning for Python)는 Oracle Database나 Oracle Autonomous Database를 사용하여 데이터 탐색 및 준비, 머신 러닝 모델링, 솔루션 배포 등의 머신 러닝 프로세스를 지원하는 Python API입니다.
이번 ORACLE 23ai 에서 추가된 기능으로 사전 학습된 모델(Pretrainded Model)을 ONNX 형식으로 변환하여 사용할 수 있습니다. OML4Py는 Hugging Face의 텍스트 변환기를 ONNX 형식 모델로 변환하여 사용할 수 있도록 합니다. OML4Py는 또한 필요한 토큰화 및 후처리를 추가합니다. 그런 다음 결과 ONNX 파이프라인을 데이터베이스로 가져와 AI 벡터 검색을 위한 임베딩을 생성하는 데 사용할 수 있습니다.
1.OML4Py Server : Python을 사용하여 데이터 분석 및 머신러닝 작업을 수행할 수 있게 해주는 서버 측 컴포넌트입니다. 주요기능은 다음과 같습니다.
고성능 컴퓨팅: 대규모 데이터 처리와 복잡한 계산을 위해 데이터베이스의 컴퓨팅 자원을 활용합니다.
데이터 이동 최소화: 데이터를 데이터베이스 내에 유지하여 네트워크를 통한 데이터 이동을 줄이고 성능을 최적화합니다.
분산 처리: 여러 사용자와 작업이 동시에 실행될 수 있도록 지원합니다.
2. OML4Py Client: OML4Py 클라이언트는 사용자들이 로컬 환경에서 Python을 사용해 Oracle Database의 머신러닝 및 데이터 분석 기능에 접근할 수 있도록 도와주는 컴포넌트입니다. 주요 기능은 다음과 같습니다.
로컬 작업 환경: 사용자가 친숙한 Python 인터페이스를 사용해 데이터 분석 및 머신러닝 작업을 수행할 수 있습니다.
서버와의 통신 : OML4Py 서버와 연결하여 데이터베이스 내에서 고성능 연산을 실행하고 결과를 받아올 수 있습니다.
통합 환경 : SQL 및 Python을 통합하여 작업을 수행할 수 있습니다.
오라클이 서버와 클라이언트로 나눈 이유에 대해서는 아래와 같을 것이라고 생각이 됩니다
자원 최적화: 서버는 고성능 하드웨어와 데이터베이스에 직접 접근하여 대규모 데이터를 효율적으로 처리하고, 클라이언트는 로컬 환경에서 사용자 친화적인 인터페이스를 제공합니다.
분산 작업: 서버는 연산 집약적인 작업을 처리하고, 클라이언트는 이를 요청하고 결과를 받아보는 방식으로 작업을 분산하여 처리 효율을 높입니다.
보안 및 관리: 서버 측에서 데이터를 중앙에서 관리하고, 클라이언트는 필요한 부분만 접근하도록 하여 보안과 관리 측면에서 유리합니다.
참고 : 23ai의 경우 Python을 빌드하는 것은 클라이언트에만 필요합니다. 데이터베이스에는 Python 3.12.1이 있습니다 $ORACLE_HOME/python. Hugging Face의 텍스트 변환기를 ONNX 형식 모델로 변환하여 지원하는 기능은 OML4Py 클라이언트에서만 작동합니다. OML4Py 서버에서는 지원되지 않습니다.
인터넷을 사용할 수 있는 환경에서는 ORACLE DOCUMENT를 따라하면 잘 설치가 되었기에 설치과정을 생략하고 폐쇄망 설치 내용만 정리했습니다.
폐쇄망 환경에서 PIP 를 자유롭게 사용할 수 없어 OML4Py 서버 설치 시 ORACLE 유저의 Python 패키지의 버전 차이로 오라클 엔진에서 필요한 패키지를 설치 할 수 없었기에, 클라이언트 설치를 먼저 진행하였습니다.
로컬에서 Oracle Python API인 OML4Py를 사용하기 위해 OML4Py 클라이언트 버전을 설치하겠습니다. 현재 저희 환경은 리눅스 서버이고, 클라이언트 환경 역시 설치된 리눅스 서버로진행하기 때문에 리눅스에 OML4Py Client를 설치하였습니다.
유저를 ORACLE이 아닌 새로운 유저로 생성 후 Python을 설치를 할 수도 있지만, Python 패키지 설치를 생략하려고 ORACLE_HOME에 설치된 Python을 사용하기 위해 ORACLE 유저에서 클라이언트 설치를 진행하였습니다. (위에서 OML4Py 서버 설치시에 환경변수를 추가했습니다.)
OML4Py 클라이언트 설치 목차
환경변수 추가
라이브러리 설치
패키지 설치
OML4Py 클라이언트 설치
OML4Py 클라이언트 설치
1) 환경변수추가 oracle 유저 환경변수에 python path를 추가합니다.
su – oracle
vi .bash_profiel
export ORACLE_BASE=/opt/oracle
export ORACLE_HOME=$ORACLE_BASE/product/23ai/dbhomeFree
export ORACLE_SID=FREE
export NLS_LANG=KOREAN_KOREA.UTF8
export PYTHONHOME=$ORACLE_HOME/python
export PATH=$ORACLE_HOME/bin:$PYTHONHOME/bin:$PATH
export LD_LIBRARY_PATH=$PYTHONHOME/lib:$LD_LIBRARY_PATH
#실행로그
[root@devaidbv1 ~]# sudo yum install perl-Env libffi-devel openssl openssl-devel tk-devel xz-devel zlib-devel bzip2-devel readline-devel libuuid-devel ncurses-devel
마지막 메타자료 만료확인(2:40:09 이전): 2024년 08월 01일 (목) 오후 12시 13분 20초.
꾸러미 openssl-1:1.1.1k-9.el8_7.x86_64가 이미 설치되어 있습니다.
꾸러미 openssl-devel-1:1.1.1k-9.el8_7.x86_64가 이미 설치되어 있습니다.
꾸러미 xz-devel-5.2.4-4.el8_6.x86_64가 이미 설치되어 있습니다.
꾸러미 zlib-devel-1.2.11-25.el8.x86_64가 이미 설치되어 있습니다.
종속성이 해결되었습니다.
==============================================================================================================================================
꾸러미 구조 버전 저장소 크기
==============================================================================================================================================
설치 중:
bzip2-devel x86_64 1.0.6-26.el8 BaseRepo 224 k
libffi-devel x86_64 3.1-24.el8 BaseRepo 29 k
libuuid-devel x86_64 2.32.1-43.0.1.el8 BaseRepo 99 k
ncurses-devel x86_64 6.1-10.20180224.el8 BaseRepo 528 k
perl-Env noarch 1.04-395.el8 AppstreamRepo 21 k
readline-devel x86_64 7.0-10.el8 BaseRepo 204 k
tk-devel x86_64 1:8.6.8-1.el8 AppstreamRepo 498 k
종속 꾸러미 설치 중:
expat-devel x86_64 2.2.5-11.0.1.el8 BaseRepo 57 k
fontconfig-devel x86_64 2.13.1-4.el8 BaseRepo 151 k
freetype-devel x86_64 2.9.1-9.el8 BaseRepo 464 k
libX11-devel x86_64 1.6.8-6.el8 AppstreamRepo 976 k
libXau-devel x86_64 1.0.9-3.el8 AppstreamRepo 21 k
libXft-devel x86_64 2.3.3-1.el8 AppstreamRepo 25 k
libXrender-devel x86_64 0.9.10-7.el8 AppstreamRepo 22 k
libpng-devel x86_64 2:1.6.34-5.el8 BaseRepo 327 k
libxcb-devel x86_64 1.13.1-1.el8 AppstreamRepo 1.1 M
ncurses-c++-libs x86_64 6.1-10.20180224.el8 BaseRepo 58 k
tcl-devel x86_64 1:8.6.8-2.el8 BaseRepo 190 k
tk x86_64 1:8.6.8-1.el8 AppstreamRepo 1.6 M
xorg-x11-proto-devel noarch 2020.1-3.el8 AppstreamRepo 280 k
연결 요약
==============================================================================================================================================
설치 20 꾸러미
전체 크기: 6.7 M
설치된 크기 : 17 M
진행할까요? [y/N]: y
꾸러미 내려받기 중:
연결 확인 실행 중
연결 확인에 성공했습니다.
연결 시험 실행 중
연결 시험에 성공했습니다.
연결 실행 중
준비 중 : 1/1
설치 중 : xorg-x11-proto-devel-2020.1-3.el8.noarch 1/20
설치 중 : libXau-devel-1.0.9-3.el8.x86_64 2/20
설치 중 : libxcb-devel-1.13.1-1.el8.x86_64 3/20
설치 중 : libX11-devel-1.6.8-6.el8.x86_64 4/20
설치 중 : libXrender-devel-0.9.10-7.el8.x86_64 5/20
구현 중 : tk-1:8.6.8-1.el8.x86_64 6/20
설치 중 : tk-1:8.6.8-1.el8.x86_64 6/20
구현 중 : tk-1:8.6.8-1.el8.x86_64 6/20
설치 중 : tcl-devel-1:8.6.8-2.el8.x86_64 7/20
설치 중 : ncurses-c++-libs-6.1-10.20180224.el8.x86_64 8/20
설치 중 : ncurses-devel-6.1-10.20180224.el8.x86_64 9/20
설치 중 : libuuid-devel-2.32.1-43.0.1.el8.x86_64 10/20
설치 중 : libpng-devel-2:1.6.34-5.el8.x86_64 11/20
설치 중 : expat-devel-2.2.5-11.0.1.el8.x86_64 12/20
설치 중 : bzip2-devel-1.0.6-26.el8.x86_64 13/20
설치 중 : freetype-devel-2.9.1-9.el8.x86_64 14/20
설치 중 : fontconfig-devel-2.13.1-4.el8.x86_64 15/20
설치 중 : libXft-devel-2.3.3-1.el8.x86_64 16/20
설치 중 : tk-devel-1:8.6.8-1.el8.x86_64 17/20
설치 중 : readline-devel-7.0-10.el8.x86_64 18/20
구현 중 : readline-devel-7.0-10.el8.x86_64 18/20
설치 중 : perl-Env-1.04-395.el8.noarch 19/20
설치 중 : libffi-devel-3.1-24.el8.x86_64 20/20
구현 중 : libffi-devel-3.1-24.el8.x86_64 20/20
확인 중 : bzip2-devel-1.0.6-26.el8.x86_64 1/20
확인 중 : expat-devel-2.2.5-11.0.1.el8.x86_64 2/20
확인 중 : fontconfig-devel-2.13.1-4.el8.x86_64 3/20
확인 중 : freetype-devel-2.9.1-9.el8.x86_64 4/20
확인 중 : libffi-devel-3.1-24.el8.x86_64 5/20
확인 중 : libpng-devel-2:1.6.34-5.el8.x86_64 6/20
확인 중 : libuuid-devel-2.32.1-43.0.1.el8.x86_64 7/20
확인 중 : ncurses-c++-libs-6.1-10.20180224.el8.x86_64 8/20
확인 중 : ncurses-devel-6.1-10.20180224.el8.x86_64 9/20
확인 중 : readline-devel-7.0-10.el8.x86_64 10/20
확인 중 : tcl-devel-1:8.6.8-2.el8.x86_64 11/20
확인 중 : libX11-devel-1.6.8-6.el8.x86_64 12/20
확인 중 : libXau-devel-1.0.9-3.el8.x86_64 13/20
확인 중 : libXft-devel-2.3.3-1.el8.x86_64 14/20
확인 중 : libXrender-devel-0.9.10-7.el8.x86_64 15/20
확인 중 : libxcb-devel-1.13.1-1.el8.x86_64 16/20
확인 중 : perl-Env-1.04-395.el8.noarch 17/20
확인 중 : tk-1:8.6.8-1.el8.x86_64 18/20
확인 중 : tk-devel-1:8.6.8-1.el8.x86_64 19/20
확인 중 : xorg-x11-proto-devel-2020.1-3.el8.noarch 20/20
설치되었습니다:
bzip2-devel-1.0.6-26.el8.x86_64 expat-devel-2.2.5-11.0.1.el8.x86_64 fontconfig-devel-2.13.1-4.el8.x86_64
freetype-devel-2.9.1-9.el8.x86_64 libX11-devel-1.6.8-6.el8.x86_64 libXau-devel-1.0.9-3.el8.x86_64
libXft-devel-2.3.3-1.el8.x86_64 libXrender-devel-0.9.10-7.el8.x86_64 libffi-devel-3.1-24.el8.x86_64
libpng-devel-2:1.6.34-5.el8.x86_64 libuuid-devel-2.32.1-43.0.1.el8.x86_64 libxcb-devel-1.13.1-1.el8.x86_64
ncurses-c++-libs-6.1-10.20180224.el8.x86_64 ncurses-devel-6.1-10.20180224.el8.x86_64 perl-Env-1.04-395.el8.noarch
readline-devel-7.0-10.el8.x86_64 tcl-devel-1:8.6.8-2.el8.x86_64 tk-1:8.6.8-1.el8.x86_64
tk-devel-1:8.6.8-1.el8.x86_64 xorg-x11-proto-devel-2020.1-3.el8.noarch
완료되었습니다!
3) 파이썬 실행 경로 확인
파이썬에 접속해서 실행 위치를 확인합니다. linux 서버 설치시 기본적으로 python이 설치되어 있어서 root에서도 python접속이 됩니다. root에 설치된 파이썬은 변경 할 수 없기 때문에 반드시 oracle 계정으로 접속해서 진행하세요. root에 python 버전은 3.6.8이고, oracle 유저의 python 버전은 3.12.3 입니다.
#명령어
su - oracle
python3
import sys
print(sys.executable)
#실행로그
[root@devaidbv1 ~]# su - oracle
[oracle@devaidbv1 ~]$ python3
Python 3.12.3 (main, Jul 3 2024, 08:35:38) [GCC 8.5.0 20210514 (Red Hat 8.5.0-18.0.6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> print(sys.executable)
/opt/oracle/product/23ai/dbhomeFree/python/bin/python3
트러블슈팅 : Requirement already satisfied: numpy==1.26.4 in /opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages (1.26.4) --upgrade to force 옵션으로 설치 필요. 무시하고 넘어가면 oml import test 시에 error발생 트러블슈팅 - pip3.12 install -U transformers 진행 하지 않을시에 ONNX 파일 생성시에 에러발생 FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible.=> transformers 업데이트 진행 >>> em.export2file("multi-qa-MiniLM-L6-cos-v1",output_dir="./") /opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/huggingface_hub/file_download.py:1150: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`. warnings.warn( pip install -U transformers
transformers가 4.38.1일때 임베딩 모델 가져오는 부분에서 에러로 transformers-4.42.4으로 업그레이드해서 진행함.
iii) OML4Py Client 설치 클라이언트설치스크립트실행합니다.(경로:oml4py 압축해제한디렉토리)
#명령어
perl -Iclient client/client.pl
* 트러블슈팅- Upgrade scikit_learn from version 2.0.1 to version 1.2.1 or higher at client/client.pl line 141 => pip list | grep numpy버전이 1.26.4인지확인아닐시 1.26.4 설치 [oracle@devaidbv1 OMLP4y]$ perl -Iclient client/client.pl Oracle Machine Learning for Python 2.0 Client. Copyright (c) 2018, 2024 Oracle and/or its affiliates. All rights reserved. Checking platform .................. Pass Checking Python .................... Pass Checking dependencies .............. /u01/download/OMLP4y/check_deps.py:2: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html from pkg_resources import WorkingSet, VersionConflict, DistributionNotFound Fail ERROR: Upgrade scikit_learn from version 2.0.1 to version 1.2.1 or higher at client/client.pl line 141.
iv)OML모듈(OML4Py 클라이언트) 설치 확인
#명령어
python3
import oml
#실행로그
$ python3
Python 3.12.3 (main, Jul 3 2024, 08:35:38) [GCC 8.5.0 20210514 (Red Hat 8.5.0-18.0.6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import oml
>>>
v) OML 경로 확인
['/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/oml'] 결과 값이 나오면 정상입니다.
#명령어
python3
import oml
oml.__path__
#실행로그
[oracle@devaidbv1 OMLP4y]$ python3
Python 3.12.3 (main, Jul 3 2024, 08:35:38) [GCC 8.5.0 20210514 (Red Hat 8.5.0-18.0.6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import oml
>>> oml.__path__
['/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/oml']
[oracle@devaidbv1 server]$ sqlplus / as sysdba
SQL> show con_name
CON_NAME
------------------------------
CDB$ROOT
iii. log 캡처를 위한 spool
SQL> spool oml4py_install_root.txt
iv. OML4Py 서버 설치를 위한 스크립트 실행
SQL> @pyqcfg.sql SYSAUX TEMP
SQL> spool off;
v. spool 한 파일을 열어 설치중에 발생한 오류가 있는지 확인
vi oml4py_install_root.txt
vi.PDB에서 OML4Py 설치 스크립트 실행
#명령어
sqlplus / as sysdba
show pdbs
spool oml4py_install_pdb.txt
alter session set container=FREEPDB1;
show con_name
@pyqcfg.sql SYSAUX TEMP
#실행로그
[oracle@localhost server]$ sqlplus / as sysdba
SQL*Plus: Release 23.0.0.0.0 - Production on 금 7월 26 10:04:43 2024
Version 23.4.0.24.05
Copyright (c) 1982, 2024, Oracle. All rights reserved.
다음에 접속됨:
Oracle Database 23ai Free Release 23.0.0.0.0 - Develop, Learn, and Run for Free
Version 23.4.0.24.05
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FREEPDB1 READ WRITE NO
SQL> spool oml4py_install_pdb.txt
SQL> alter session set container=FREEPDB1;
세션이 변경되었습니다.
SQL> show con_name
CON_NAME
------------------------------
FREEPDB1
SQL> @pyqcfg.sql SYSAUX TEMP
spool off;
vii. 설치 로그를 열어 오류가 있는지 확인
vi oml4py_install_pdb.txt
4)서버의OML4Py구성 확인
i. PDB 접속
#명령어
sqlplus / as sysdba
alter session set container=freepdb1;
ii.OML4Py 구성 확인
#명령어
select * from sys.pyq_config;
#실행로그
[oracle@devaidbv1 server]$ sqlplus / as sysdba
SQL*Plus: Release 23.0.0.0.0 - for Oracle Cloud and Engineered Systems on 목 8월 1 18:49:53 2024
Version 23.5.0.24.07
Copyright (c) 1982, 2024, Oracle. All rights reserved.
다음에 접속됨:
Oracle Database 23ai Free Release 23.0.0.0.0 - Develop, Learn, and Run for Free
Version 23.5.0.24.07
SQL> alter session set container=freepdb1;
세션이 변경되었습니다.
SQL> select * from sys.pyq_config;
NAME
--------------------------------------------------------------------------------
VALUE
--------------------------------------------------------------------------------
PYTHONHOME
/opt/oracle/product/23ai/dbhomeFree/python
PYTHONPATH
/opt/oracle/product/23ai/dbhomeFree/oml4py/modules
VERSION
2.0
NAME
--------------------------------------------------------------------------------
VALUE
--------------------------------------------------------------------------------
PLATFORM
ODB
DSWLIST
oml.*;pandas.*;numpy.*;matplotlib.*;sklearn.*
OML4Py 유저 생성
유저를생성하는방법에는 2가지가있습니다.
일반 user 생성쿼리로생성후권한을추가하는법과, 오라클에서제공하는 pyquser.sql 스크립트를사용하는방법이있습니다. 저는 오라클에서 제공하는 쿼리로 유저를 생성했습니다. user 생성전 tablespace 생성은스크립트사용유무와상관없이생성후진행해야합니다.
1. Tablespace 생성
FREE버전에서는ORACLE_HOME이/opt/밑으로강제되기에 저의 서버 환경에서는 root쪽 공간이 부족하여 /opt/oracle을심볼릭링크로/u01/opt/oracle로걸었습니다. (root에는공간이부족하여2T가마운트된u01로심볼릭링크) 따라서테이블스페이스생성시에는생성위치를/u01/oracle/FREE/FREEPDB1/으로했습니다.
#명령어
CREATE TABLESPACE TS_ONN DATAFILE '/u01/oracle/FREE/FREEPDB1/ts_onn_1.dbf' SIZE 100M AUTOEXTEND ON NEXT 100M MAXSIZE 30G EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
* 참고 : tablespace 삭제 쿼리 : drop tablespace TS_ONN including contents and datafiles;
#실행로그
SQL> @pyquser.sql ONN TS_ONN TEMP unlimited pyqadmin
세션이 변경되었습니다.
password의 값을 입력하십시오: oracle
구 1: create user &&1 identified by &password
신 1: create user ONN identified by oracle
구 2: default tablespace &&2
신 2: default tablespace TS_ONN
구 3: temporary tablespace &&3
신 3: temporary tablespace TEMP
구 4: quota &&4 on &&2
신 4: quota unlimited on TS_ONN
사용자가 생성되었습니다.
구 4: 'create procedure, create mining model to &&1';
신 4: 'create procedure, create mining model to ONN';
구 6: IF lower('&&5') = 'pyqadmin' THEN
신 6: IF lower('pyqadmin') = 'pyqadmin' THEN
구 7: execute immediate 'grant PYQADMIN to &&1';
신 7: execute immediate 'grant PYQADMIN to ONN';
PL/SQL 처리가 정상적으로 완료되었습니다.
세션이 변경되었습니다.
OML4Py연결 테스트
마지막으로 OML4Py가 잘 설치되었는지 확인하기 위해서 테스트를 하고 설치를 종료합니다. host에 변수값을 환경에 맞게 변경하고 테스트 진행하세요. 실행로그에서 보이듯 res의 결과값이 2가 나오면 됩니다.
#명령어
python3
import oml
oml.connect(user='onn', password='oracle', host='xxx.xx.xxx.xx', port=1521, service_name='freepdb1')
oml.script.create("TEST", func='def func():return 1 + 1', overwrite=True)
res = oml.do_eval(func='TEST')
res
#실행로그
$ python3
Python 3.12.3 (main, Jul 3 2024, 08:35:38) [GCC 8.5.0 20210514 (Red Hat 8.5.0-18.0.6)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import oml
>>> oml.connect(user='onn', password='oracle', host='xxx.xx.xxx.xx', port=1521, service_name='freepdb1')
>>> oml.script.create("TEST", func='def func():return 1 + 1', overwrite=True)
>>> res = oml.do_eval(func='TEST')
>>> res
2
트러블슈팅 - oracledb.exceptions.DatabaseError: ORA-12541: 접속할수없습니다. host xx.xxx.xx.x port 1521에리스너가없습니다. ·=> 리스너설정참고하여해결 >>> oml.connect(user='onn', password='oracle', host='xx.xxx.xx.x', port=1521, service_name='freepdb1') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "oml/core/methods.py", line 183, in oml.core.methods.connect File "/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/oracledb/connection.py", line 1158, in connect return conn_class(dsn=dsn, pool=pool, params=params, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/oracle/product/23ai/dbhomeFree/python/lib/python3.12/site-packages/oracledb/connection.py", line 544, in __init__ impl.connect(params_impl, pool_impl) File "src/oracledb/impl/thick/connection.pyx", line 494, in oracledb.thick_impl.ThickConnImpl.connect File "src/oracledb/impl/thick/utils.pyx", line 446, in oracledb.thick_impl._raise_from_info oracledb.exceptions.DatabaseError: ORA-12541: 접속할수 없습니다. host xx.xxx.xx.x port 1521에 리스너가 없습니다. 도움말: https://docs.oracle.com/error-help/db/ora-12541/